Learning Mode¶
What if users don't have a custom Glue job to be deployed but still they want to see and learn more about all the pieces needed to make a Glue job run in AWS? Well, the learning mode on terraglue can be used to deploy a preconfigured Glue job with everything is needed to see things running in practice.
Check the home page to see all things that happen in the target AWS account when we call terraglue on learnind mode.
Structuring a Terraform Project¶
If you checked the production mode demo you saw that the Terraform project structured in that context was a little bit more complex. For this demo, as we are talking about using terraglue to deploy a preconfigured Glue job, we will only need a main.tf file to put all Terraform code that is required.
Why do I need only a main.tf Terraform file when using terraglue on learning mode?
Well, there is no need to have different folders in our project to address Glue scripts files, policies or anything. By using terraglue on learning mode, all those elements, files and folders are located inside the module.
You can check all of them on the .terraform/ folder after running the terraform init command.
If you need more information about the structure of a Terraform project you can check the official Hashicorp documentation about it.
Collecting Terraform Data Sources¶
Once we structured the Terraform project, let's start by collecting some Terraform data sources that will be used along the project. Terraform data sources can improve the development of a Terraform project in a lot of aspects. In the end, this is not a required step, but it can be considered as a good practice according to which resources will be declared and which configurations will be applied.
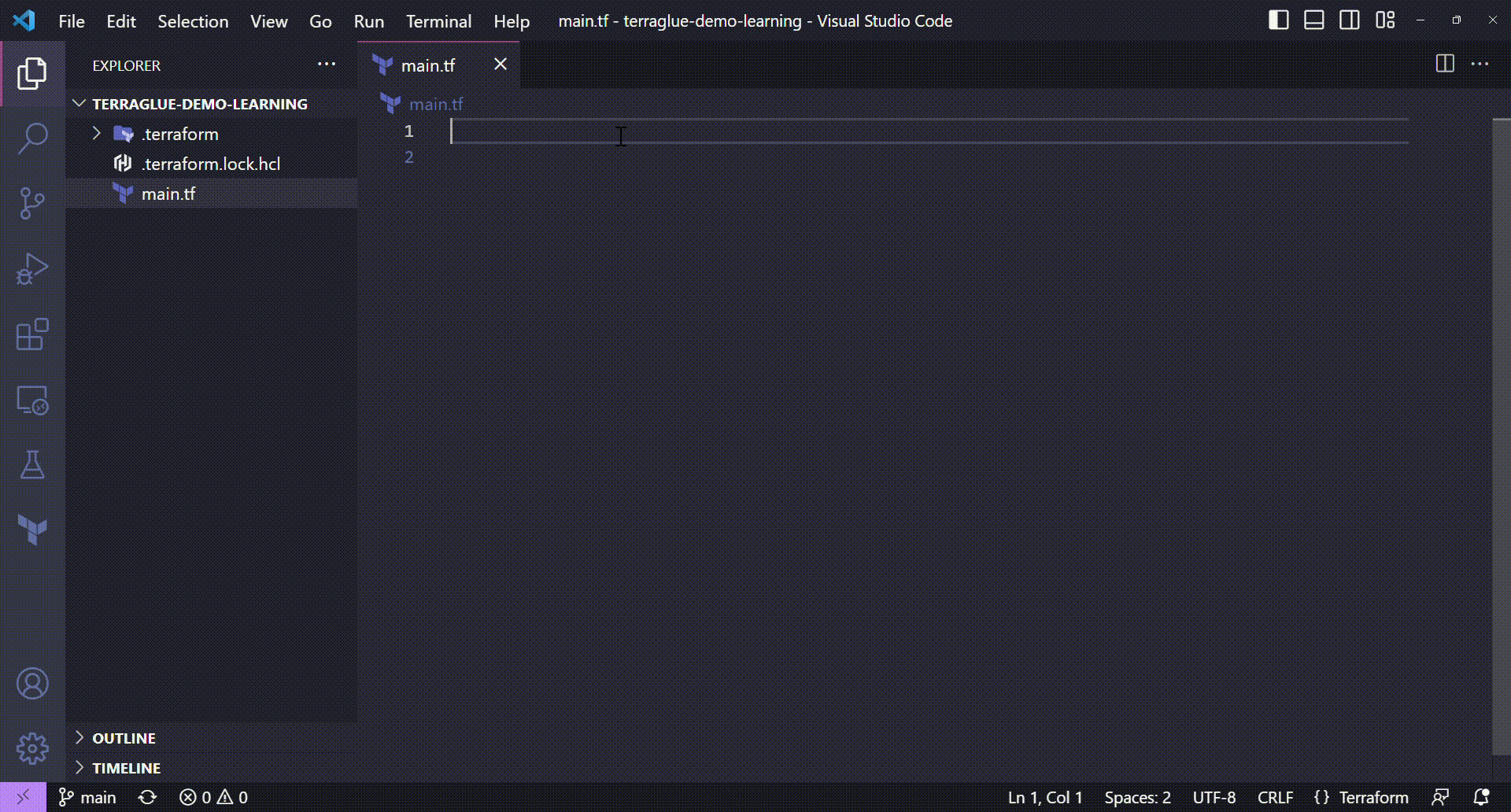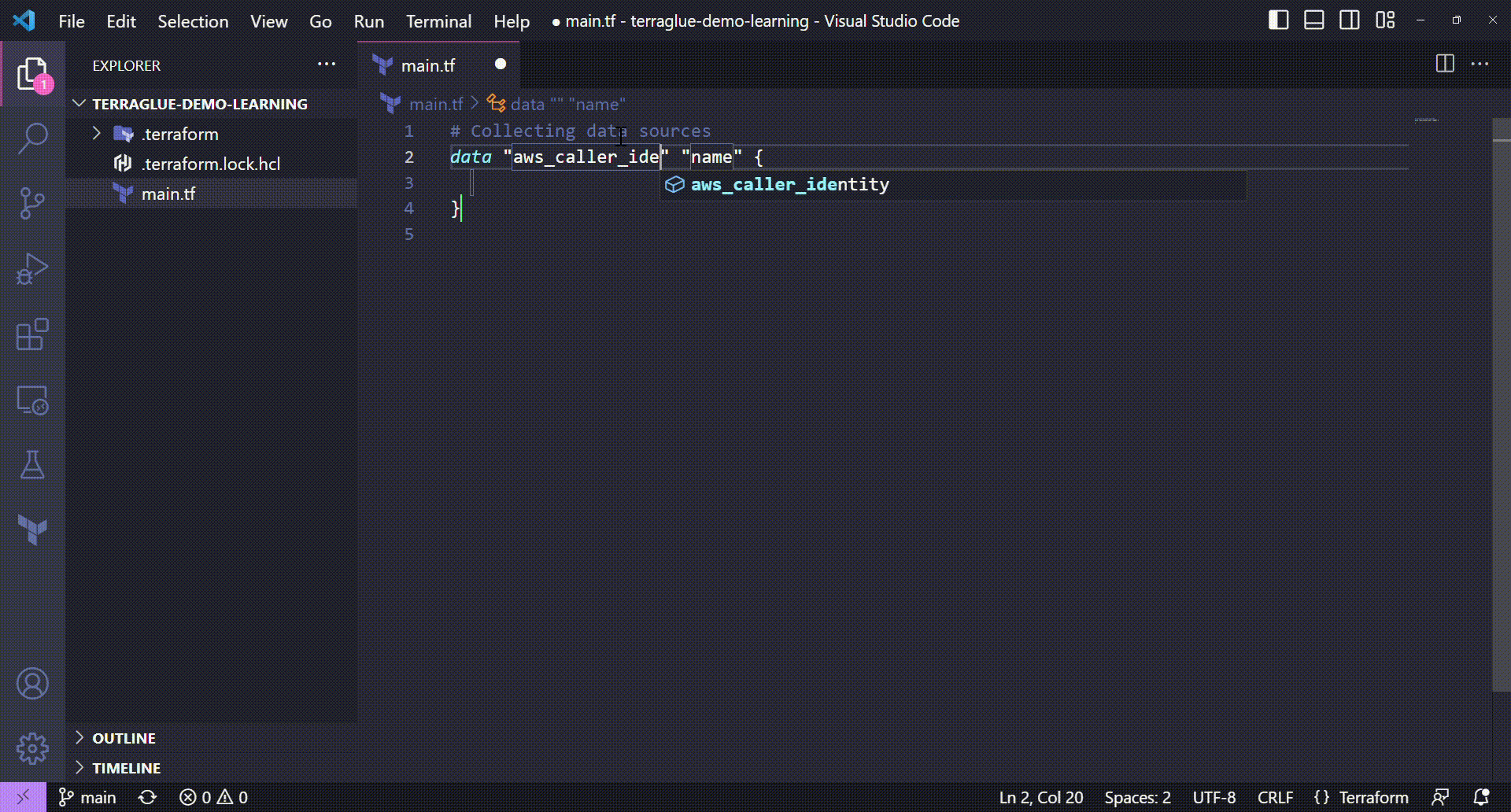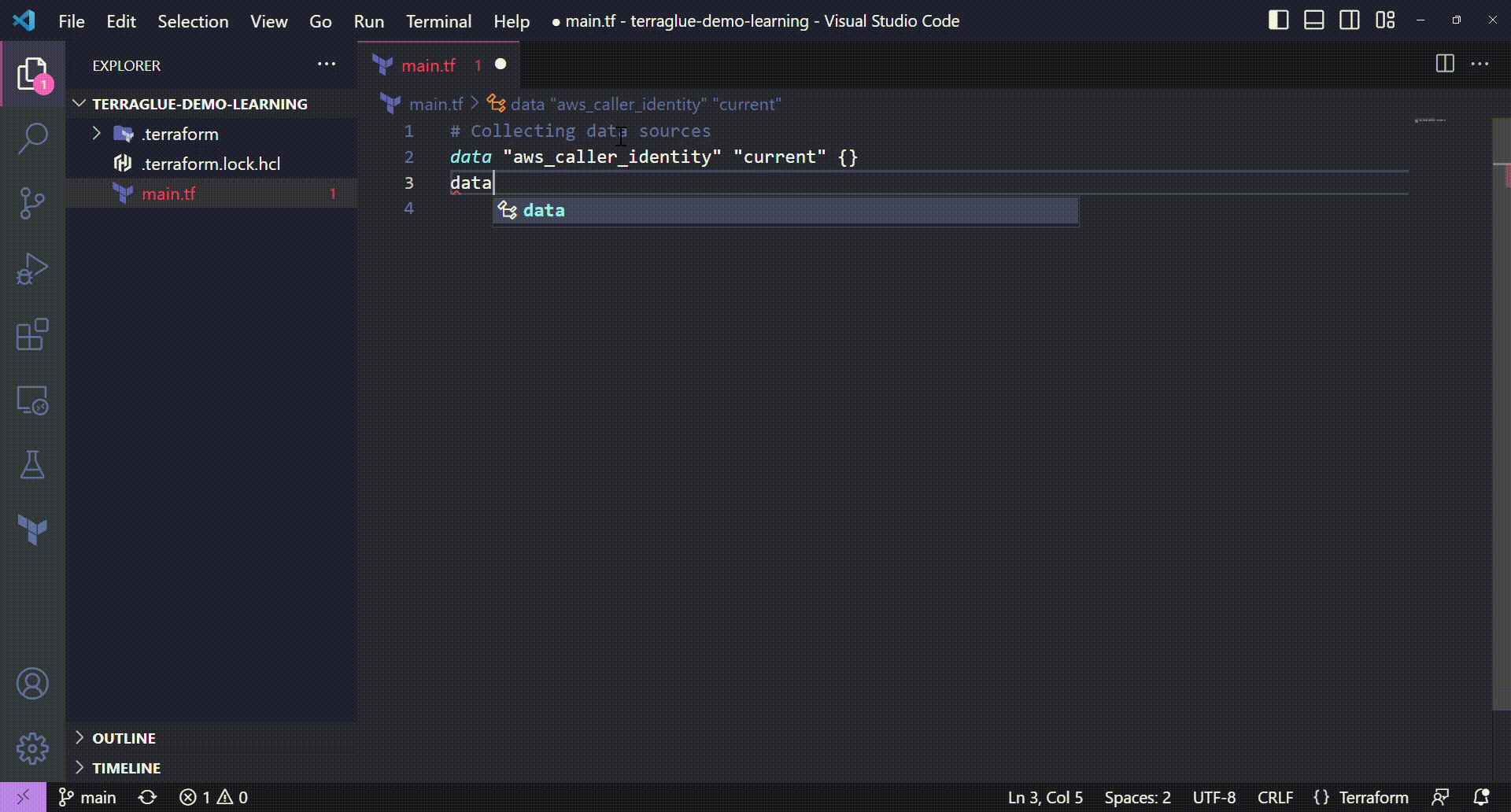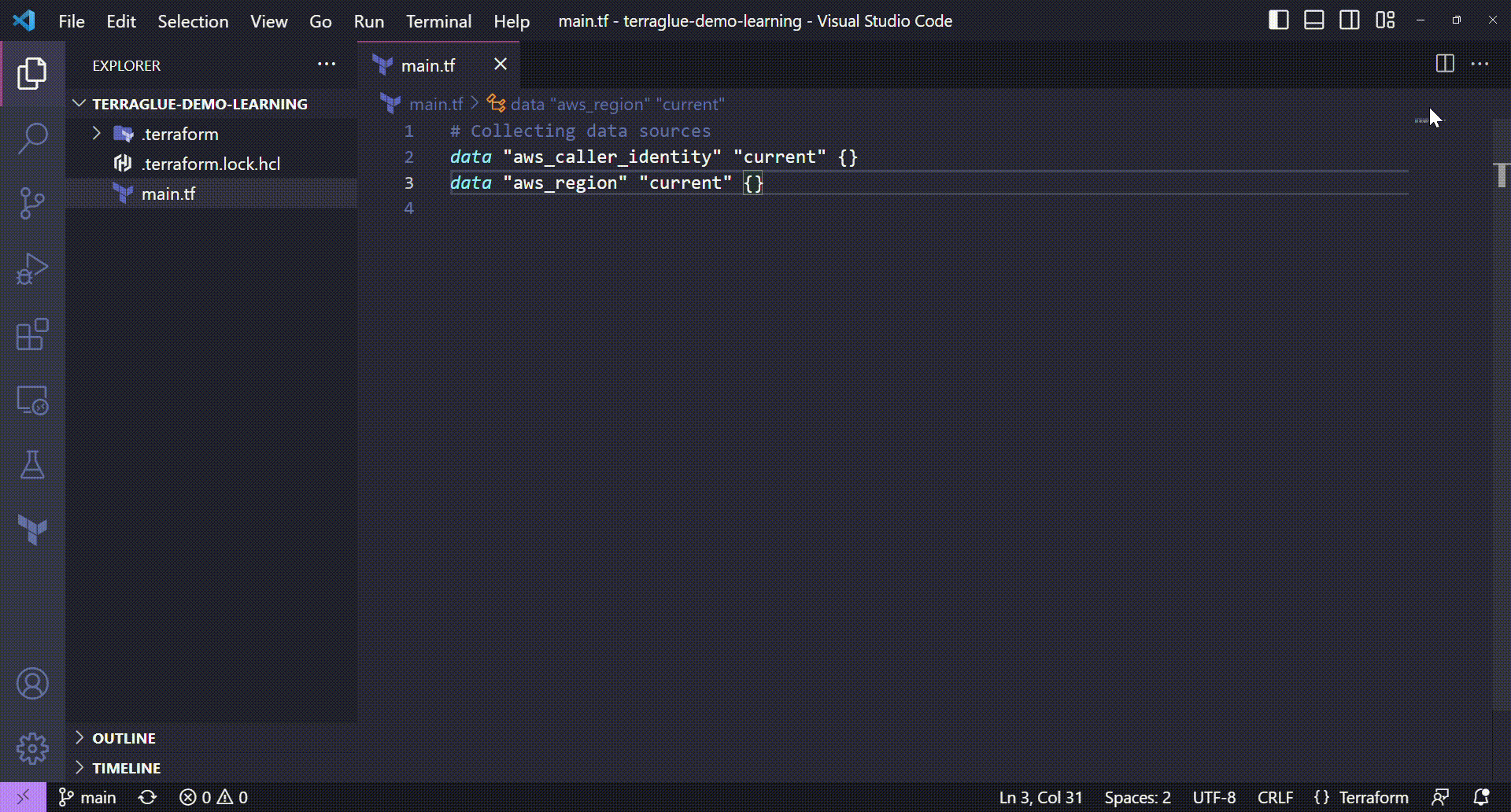
So, let's take our main.tf file and get the three Terraform data sources stated balow:
- A aws_caller_identity data source to extract the user account id
- A aws_region data source to get the target AWS region
Collecting Terraform data sources
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
Before calling terraglue module, let's call the datadelivery module in order to deploy buckets, data files, catalog tables and other useful things that is mandatory to use terraglue on learning mode!
Configuring Datadelivery¶
datadelivery is an open source Terraform module that provides an infrastructure toolkit to be deployed in any AWS account in order to help users to explore analytics services like Athena, Glue, EMR, Redshift and others. It does that by uploading and cataloging public datasets that can be used for multiple purposes, either to create jobs or just to query data using AWS services.
When we use terraglue on learning mode, the Glue job deployed on the AWS target account uses buckets and tables delivered by datalivery module. That's why we need to combine both solutions in order to reach the final goal.
Calling datadelivery module
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
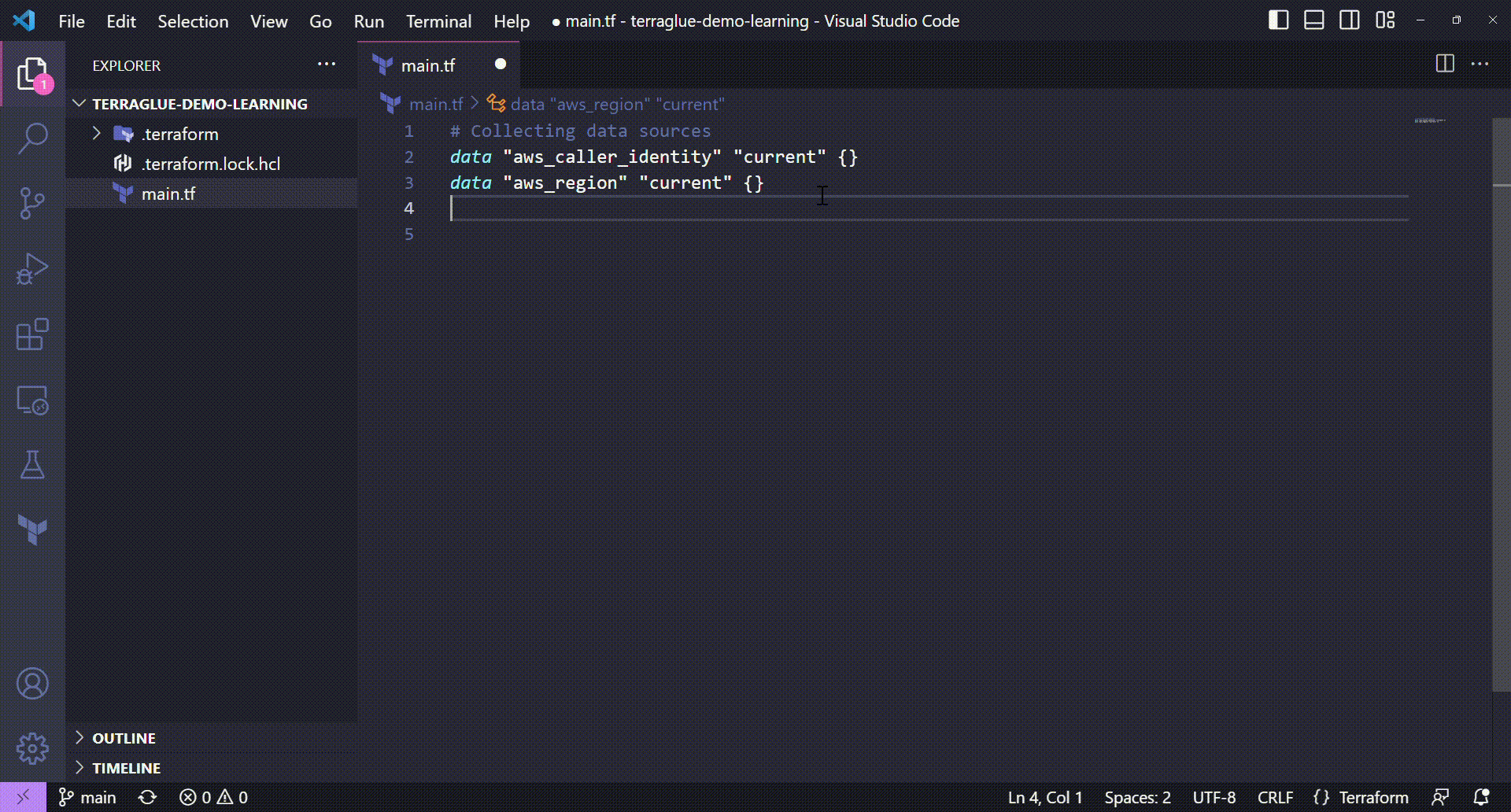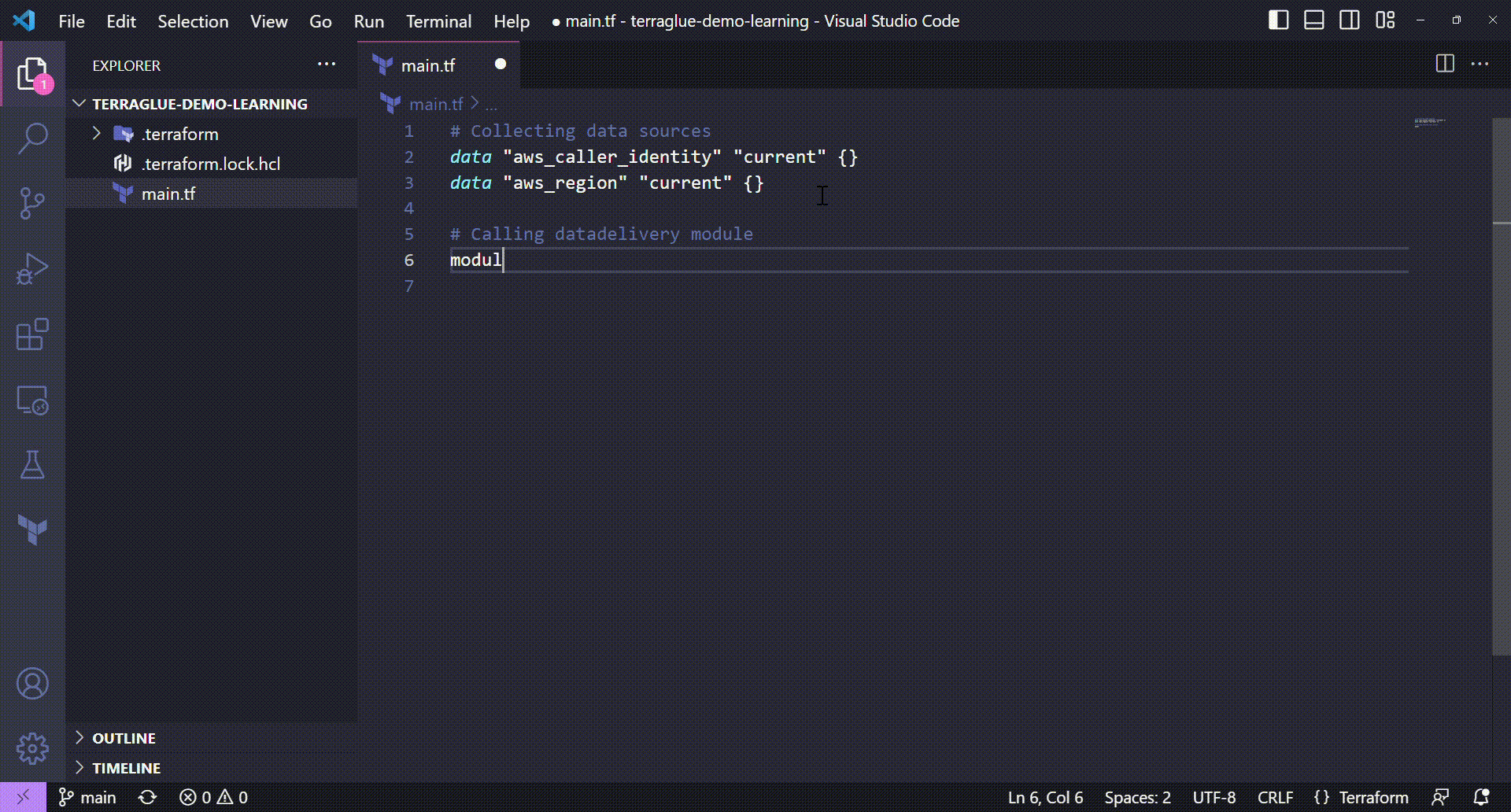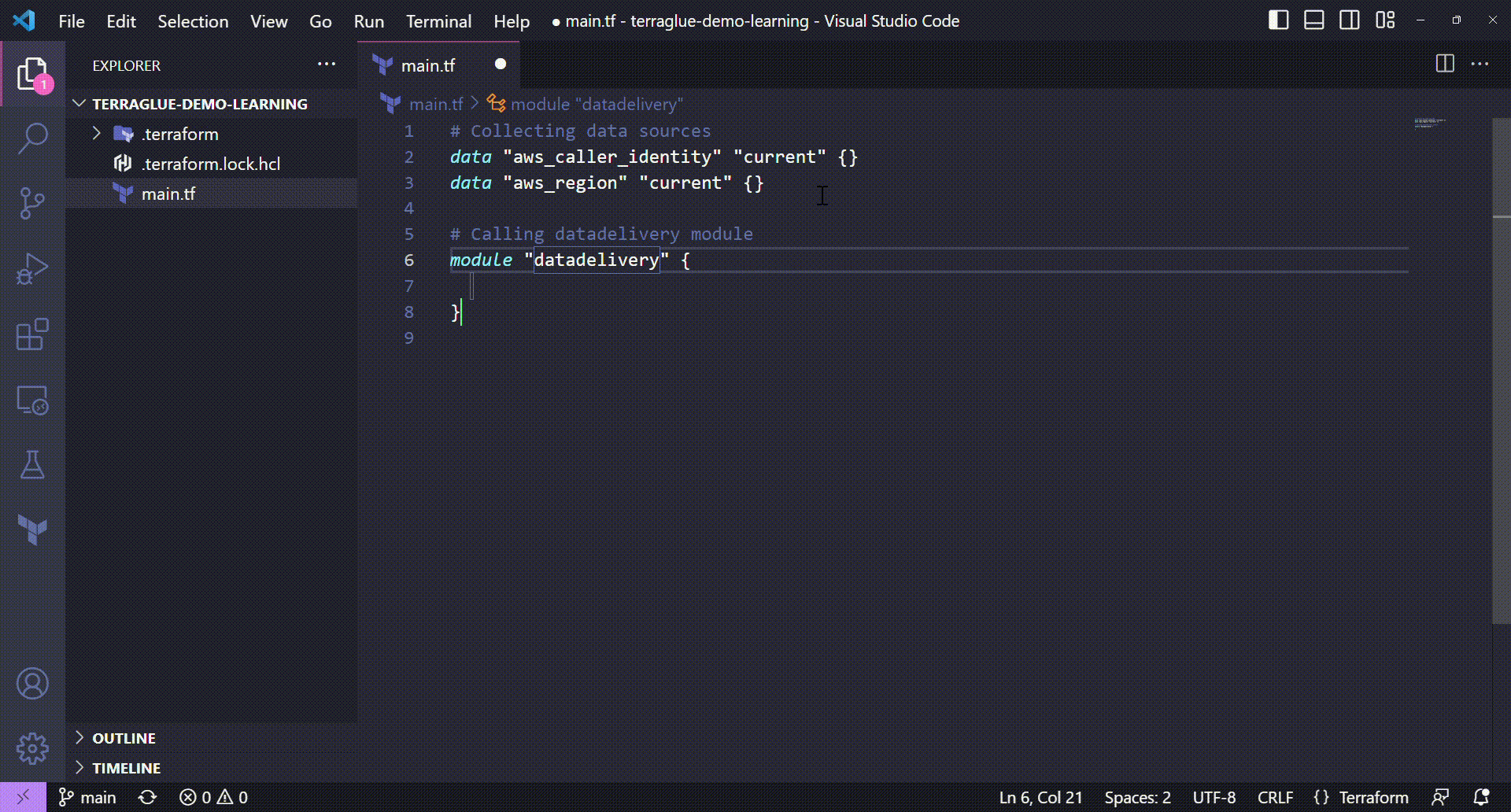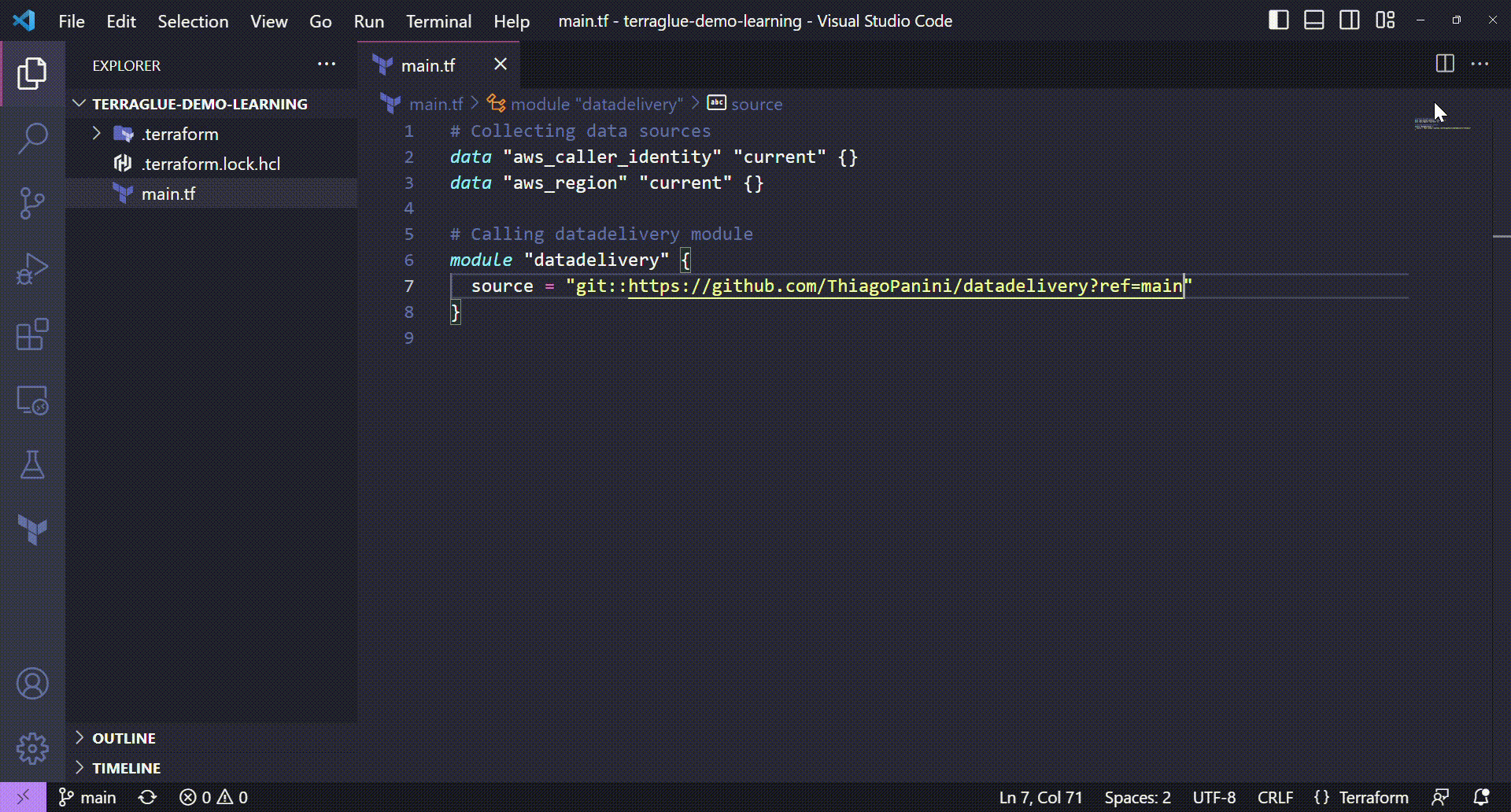
# Calling datadelivery module
module "datadelivery" {
source = "git::https://github.com/ThiagoPanini/datadelivery?ref=main"
}
Configuring Terraglue¶
Now we're ready to call terraglue. Unlike the production mode (the default one), the learning mode just need to be passed on mode module variable and nothins more is needed.
Calling The Source Module¶
This section is all about showing how to call the terraglue module directly from GitHub.
Calling terraglue module

💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
# Calling datadelivery module
module "datadelivery" {
source = "git::https://github.com/ThiagoPanini/datadelivery?ref=main"
}
# Calling terraglue module on learning mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
mode = "learning"
}
Setting Up S3 and Job Outputs¶
The only thing that is required when calling terraglue on learning mode is the set up three variables:
glue_scripts_bucket_name: to tell terraglue the name of the bucket where the script files are storedjob_output_bucket_nameto tell terraglue the name of the output bucket that will store the table generated by the jobjob_output_databaseto tell terraglue the output database that will handle the catalog process of the table generated by the job
Configuring terraglue's required variables when using it on learning mode
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
# Calling datadelivery module
module "datadelivery" {
source = "git::https://github.com/ThiagoPanini/datadelivery?ref=main"
}
# Calling terraglue module on learning mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
mode = "learning"
# Setting up the scripts bucket name
glue_scripts_bucket_name = "datadelivery-glue-assets-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.name}"
# Setting up output variables
job_output_bucket_name = "datadelivery-sot-data-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.name}"
job_output_database = "db_datadelivery_sot"
# Ensuring terraglue will be deployed only after datadelivery
depends_on = [
module.datadelivery
]
}
And that's literally all! The learning mode was built to make things easiest as possible to users that don't have much experience on deploying Glue jobs in AWS. The idea is to provide an end-to-end example on how things works.
The next step is to run the Terraform commands to deploy the resources in the target AWS account.
Running Terraform Commands¶
After all this configuration journey, we now just need to plan and apply the deployment using the respective Terraform commands.
Terraform plan¶
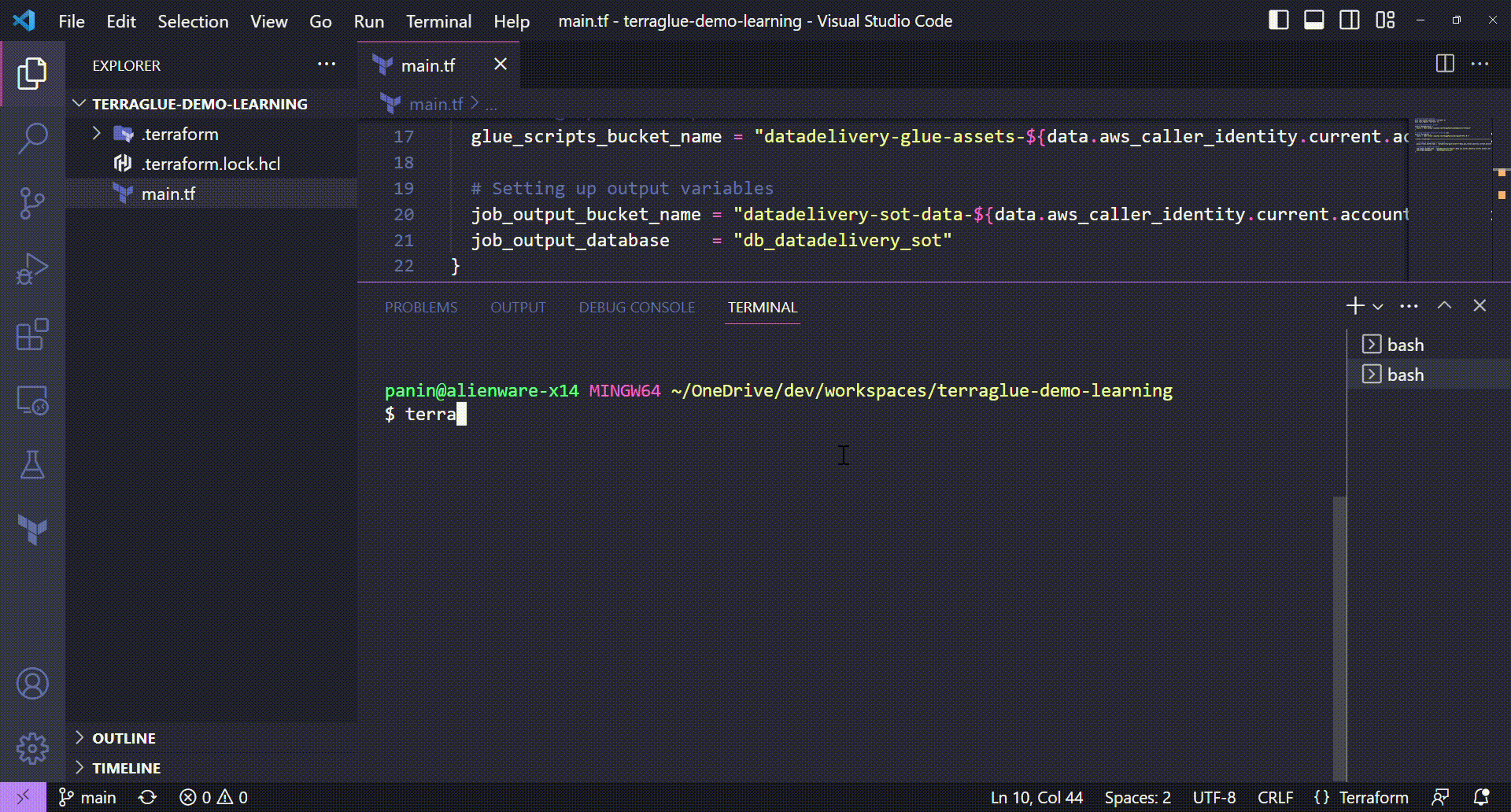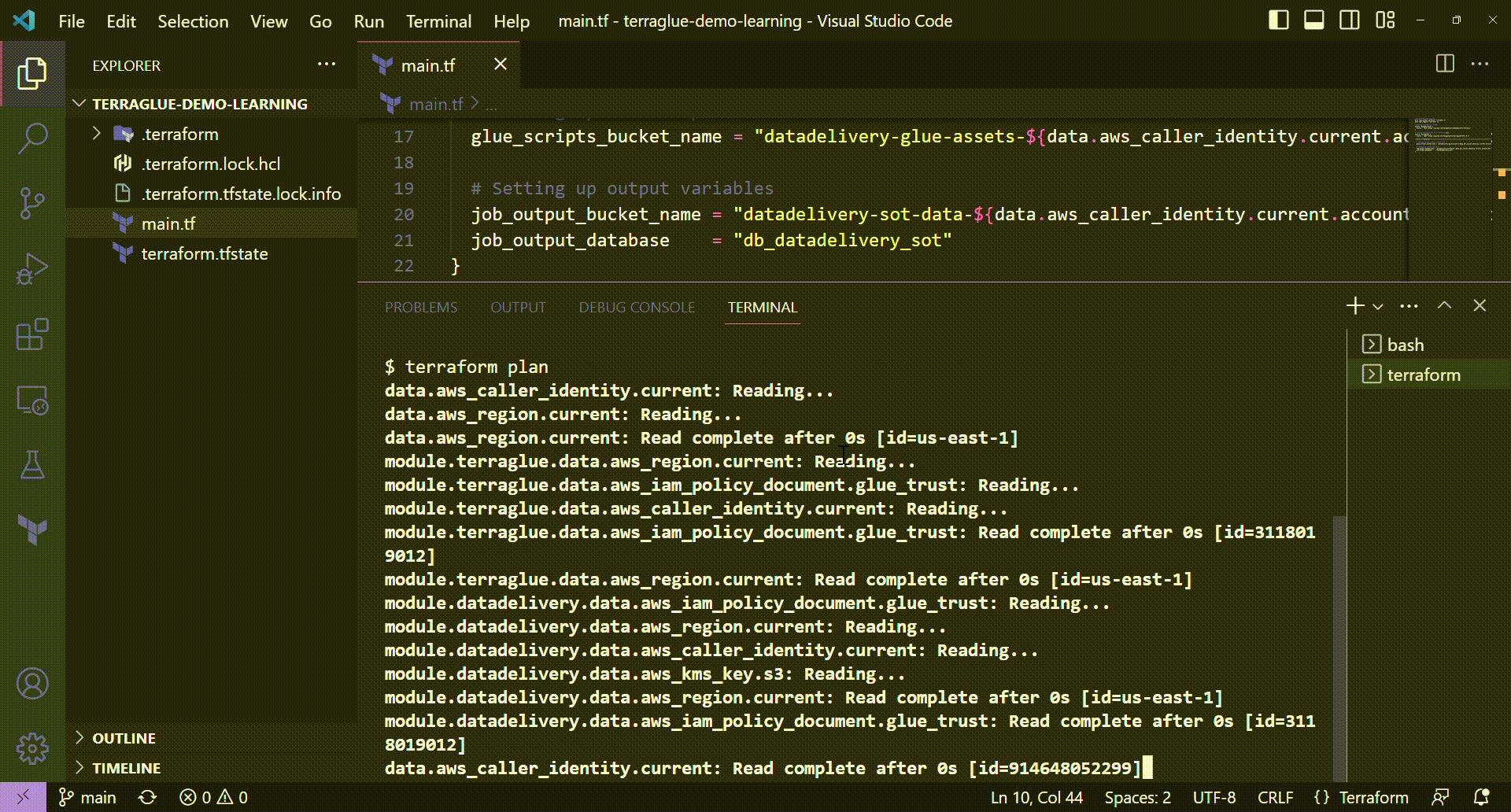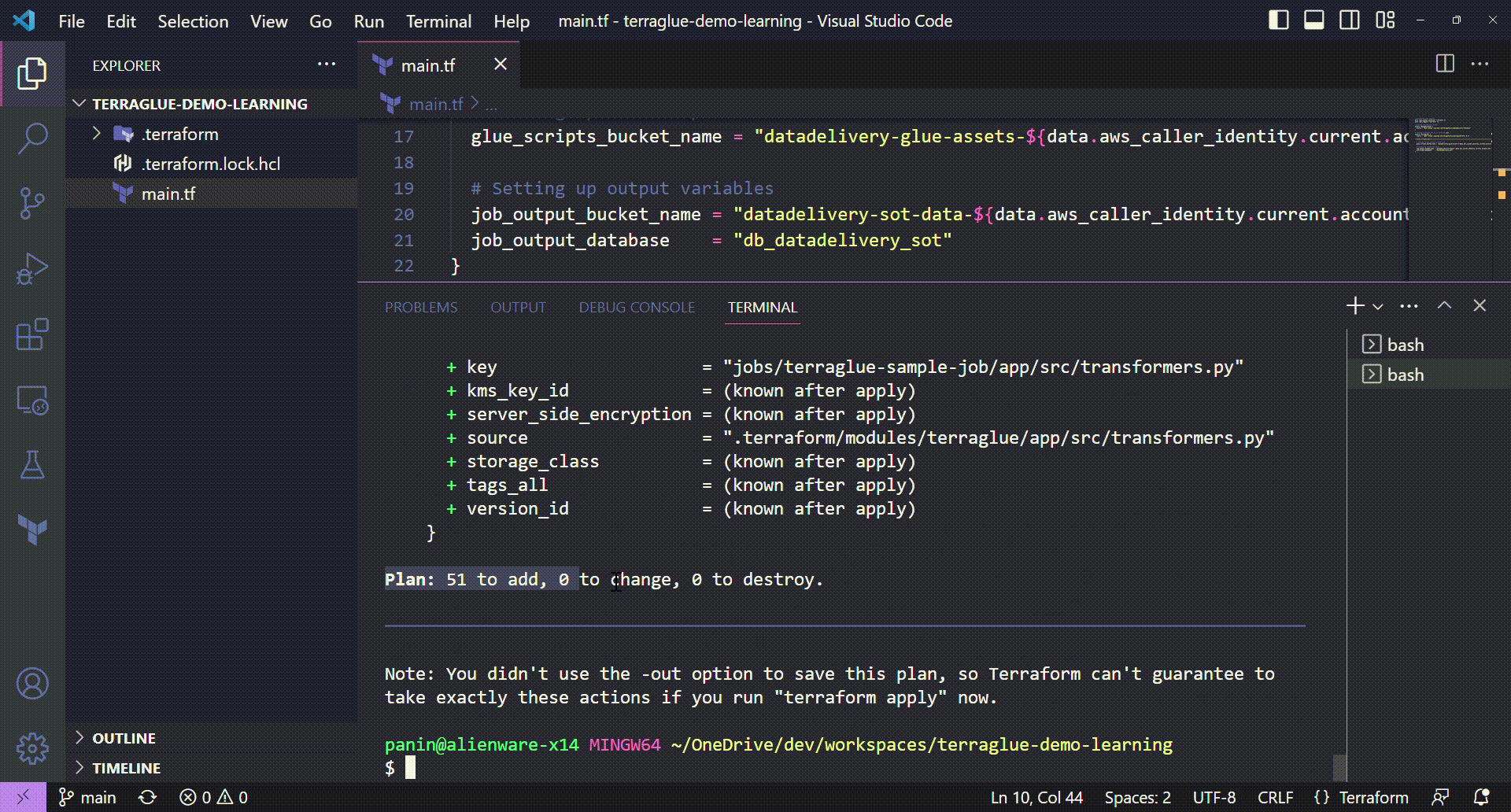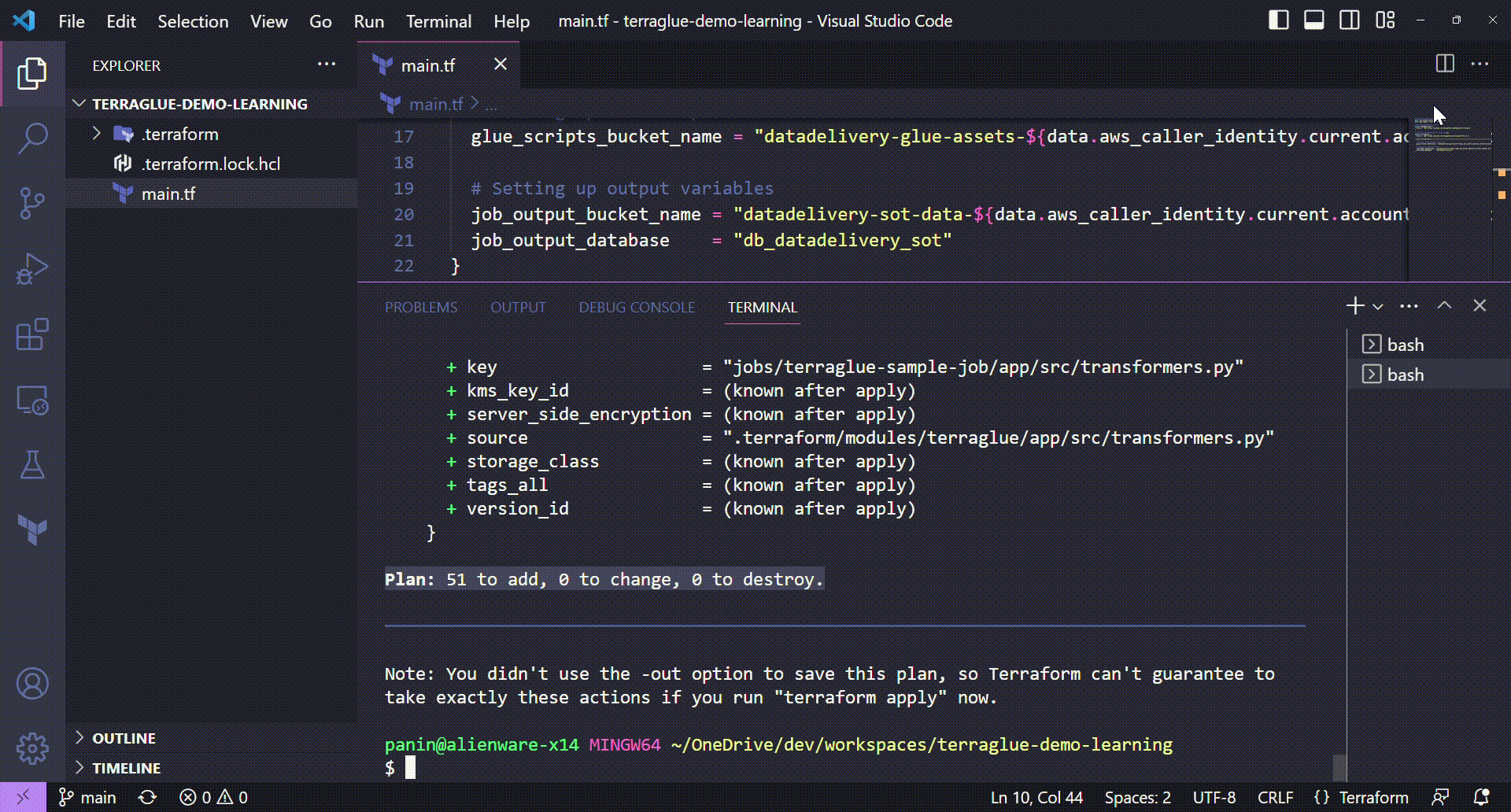
With terraform plan command, we will be able to see all the resources that will be deployed with the configuration we chose.
Running the terraform plan command
Terraform apply¶
And now we can finally deploy the infrastructure declared using the terraform apply command.
Running the terraform apply command
Deployed Resources¶
In the end, to finish this demo, let's navigate through all resources deployed in the target AWS account to see a preconfigured Glue job in scene!
A little tour through all deployed resources by terraglue
✅ I hope all the demos can help you somehow on using terraglue to learn more about how a Glue job works in practice. Keep reading the docs to become a master user in terraglue!