Project Story¶
For everyone reading this page, I ask a poetic licence to tell you a story about the challenges I faced on my analytics learning journey using AWS services and what I've done to overcome them.
🪄 In fact, this is a story about how I really started to build and share open source solutions that help people learning more about analytics services in AWS.

How it All Started¶
First of all, It's important to provide some context on how it all started. I'm an Analytics Engineer working for a financial company that has a lot of data and an increasing number of opportunities to use it. The company adopted the Data Mesh architecture to give more autonomy so the the data teams can build and share their own datasets through three different layers: SoR (System of Record), SoT (Source of Truth) and Spec (Specialized).
Know more about SoR, SoT and Spec
There are a lot of articles explaining the Data Mesh architecture and the differences between SoR, SoT and Spec layers to store and share data. In fact, this is a really useful way to improve analytics on organizations.
If you want to know a little bit more about it, there are some links that can help you on this mission:
So, the company decided to use mainly AWS services for all this journey. From analytics perspective, services like Glue, EMR, Athena and Quicksight just popped up as really good options to solve some real problems in the company.
And that's how the story begins: an Analytics Engineer trying his best to deep dive into those services in his sandbox environment for learning everything he can.
First Steps¶
Well, I had to choose an initial goal. After deciding to start learning more about AWS Glue to develop ETL jobs, I looked for documentation pages, watched some tutorial videos to prepare myself and talked to other developers to collect thoughts and experiences about the whole thing.
After a little while, I found myself ready to start building something useful. In my hands, I had an AWS sandbox account and a noble desire to learn.

An important information about the sandbox account
The use of an AWS sandbox account was due to a subscription that I had in a learning platform. This platform allowed subscribers to use an AWS environment for learning purposes and that was really nice. However, it was an ephemeral environment with an automatic shut off mechanism after a few hours. This behavior is one of the key points of the story. Keep that in mind. You will know why.
Creating the Storage Layers¶
I started to get my hands dirty by creating S3 buckets to replicate something next to a Data Lake storage architecture in a Data Mesh approach. So, one day I just logged in my sandbox AWS account and created the following buckets:
- A bucket to store SoR data
- A bucket to store SoT data
- A bucket to store Spec data
- A bucket to store Glue assets
- A bucket to store Athena query results

Uploading Files on Buckets¶
Once the storage structures was created, I started to search for public datasets do be part of my learning path. The idea was to upload some data into the buckets to make it possible to do some analytics, such as creating ETL jobs or even querying with Athena.
So, I found the excellent Brazilian E-Commerce dataset on Kaggle and it fitted perfectly. I was now able to download the data and upload it on the SoR bucket to simulate some raw data available for further analysis in an ETL pipeline.
And now my diagram was like:

Cataloging Data¶
Uploading data on S3 buckets wasn't enough to have a complete experience on applying analytics. It was important to catalog its metadata on Data Catalog to make them visible for services like Glue and Athena.
So, the next step embraced the input of all the files of Brazilian Ecommerce dataset as tables on Data Catalog. For this task, I tested two different approaches:
- Building and running
CREATE TABLEqueries on Athena based on file schema - Manually inputting fields and table properties on Data Catalog
By the way, as Athena proved itself to be a good service to start looking at cataloged data, I took the opportunity to create a workgroup with all appropriate parameters for storing query results.
And now my diagram was like:

Creating IAM Roles and Policies¶
A huge milestone was reached at that moment. I had a storage structure, I had data to be used and I had all metadata information already cataloged on Data Catalog.
What was still missing to start creating Glue jobs?
IAM roles and policies. Simple as that.
At this point I must tell you that creating IAM roles wasn't an easy step to be completed. First of all, it was a little bit difficult to understand all the permissions needed to run Glue jobs on AWS, to log steps on CloudWatch and all other things.
Suddenly I found myself searching a lot on docs pages and studying about Glue's actions to be included in my policy. After a while, I was able to create a set of policies for a good IAM role to be assumed by my future and first Glue job on AWS.
And, once again, I added more pieces on my diagram:

Creating a Glue Job¶
Well, after all those manual setup I was finally able to create my first Glue job on AWS to create ETL pipelines using public datasets available on Data Catalog.
I was really excited at that moment and the big idea was to simulate a data pipeline that read data from a SoR layer, transform it and put the curated dataset in a SoT layer. After learning a lot about awsglue library and elements like GlueContext and DynamicFrame, I was able to create a Spark application using pyspark that had enough features to reach the aforementioned goal.

And now my diagram was complete!

Not Yet: A Real Big Problem¶
As much as this is happy ending story, it doesn't happen just now.
The AWS sandbox account problem
Well, remember as a said at the beginning of the story that I had in my hands an AWS sandbox account? By sandbox account I mean a temporary environment that shuts down after a few hours.
And that's was the first big problem: I needed to recreate ALL components of the final diagram every single day.
The huge manual effort
As you can imagine, I spent almost one hour setting up things every time I wanted to practice with Glue. It was a huge manual effort and that was just almost half of the sandbox life time.
Something needed to be done.
Of course you can aske me:
Why don't you build that architecture in your personal account?
That was a nice option but the problem was the charges. I was just trying to learn Glue and running jobs multiple times (that's the expectation when you are learning) may incur some unpredictable costs.
Ok, so now I think everyone is trying to figure out what I did to solve those problems.
Yes, I found a way!
If you are still here with me, I think you would like to know it.
Terraglue: A New Project is Born¶
Well, the problems were shown and I had to think in a solution to make my life easier for that simple learning task.
The answer was right on my face all the time. If my main problem was spending time recreating infrastructure all over again, why not to automate the infrastructure creation with an IaC tool? So every time my sandbox environment expired, I could create all again with much less overhead.
That was a fantastic idea and I started to use Terraform to declare resources used in my architecture. I splitted things into modules and suddenly I had enough code to create buckets, upload data, catalog things, create IAM roles, policies and a preconfigured Glue job!
While creating all this, I just felt that everyone who had the same learning challenges that made me come to this point would enjoy the project. So I prepared it, documented it and called it terraglue.

It was really impressive how I could deploy all the components with just a couple of commands. If I used spent about 1 hour to create and configure every service manually, after terraglue that time was reduced to just seconds!
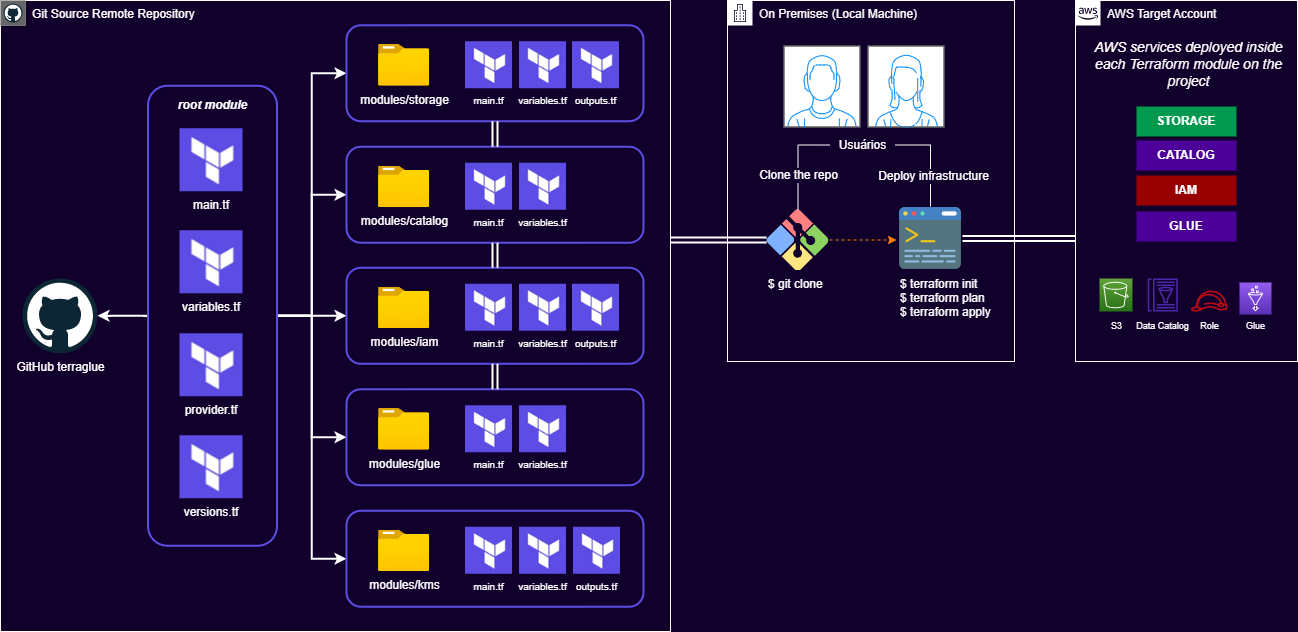
A Constant Evolution with New Solutions¶
After a while, I noticed that the terraglue project became a central point of almost everything. The source repository was composed by all the infrastructure (including buckets, data files and a Glue job) and also a Spark application with modules, classes and methods used to develop an example of a Glue job.
That wasn't a good thing.
Imagine if I started my learning journey on EMR, for example. I would almost duplicate all terraglue infrastructure to a new project to have components like buckets and data files. The same scenario can be expanded to the application layer on terraglue: I would have to copy and paste scripts from project to project. It was not scalable.
So, thinking on the best way to provide the best experience for me and for all users that could use all of this, I started to decouple the initial idea of terraglue into new open source projects. And that's the state-of-art of my solutions shelf:

In case you want to know more about each one of those new solutions, I will leave here some links for documentation pages created to give the best user experience possible:
- 🚛 datadelivery: a Terraform module that helps users to have public datasets to explore using AWS services
- 🌖 terraglue: a Terraform module that helps users to create their own preconfigured Glue jobs in their AWS account
- ✨ sparksnake: a Python package that contains useful Spark features created to help users to develop their own Spark applications
And maybe it's more to come! Terraglue was the first and, for a while, it was the only one. Suddenly, new solutions were created to fill special needs. I think this is a continuous process.
Conclusion¶
If I had to summarize this story in a few topics, I think the best sequence would be:
- 🤔 An Analytics Engineer wanted to learn AWS Glue and other analytics services on AWS
- 🤪 He started to build a complete infrastructure in his AWS sandbox account manually
- 🥲 Every time this AWS sandbox account expired, he did it all again
- 😮💨 He was tired of doing this all the time so he started to think on how to solve this problem
- 😉 He started to apply Terraform to declare all infrastructure
- 🤩 He created a pocket AWS environment to learn analytics and called it terraglue
- 🤔 He noticed that new projects could be created from terraglue in order to turn it more scalable
- 🚀 He now has a shelf of open source solutions that can help many people on learning AWS
And that's the real story about how I faced a huge problem on my learning journey and used Terraform to declare AWS components and take my learning experience to the next level.
I really hope any of the solutions presented here can be useful for anyone who needs to laearn more about analytics services on AWS.
Finally, if you like this story, don't forget to interact with me, star the repos, comment and leave your feedback. Thank you!