Production Mode¶
Let's take a deep dive on how an user can call the terraglue module to deploy it's own Glue job in AWS.
For this task, let's suppose we want to:
- Deploy a Glue job using a Spark application already available
- Create and associate an IAM role to the job
- Use an already available KMS key from the AWS account to create a Security Configuration
- Define some custom job arguments
Structuring a Terraform Project¶
By essence, the first step to be done is to set up a Terraform project. For this task, it's important to mention that everyone is free to structure a Terraform project the best way they want. To make things as simple as possible, the Terraform project structure below considers the following:
- A
app/folder to store the Spark application, additional python files and unit tests - A
policy/folder to store a JSON file that will be used to create an IAM role for the job - A
main.tfTerraform file to call terraglue module
Let's see it in a tree?
├───app
│ ├───src
│ │ main.py
│ │ utils.py
│ │
│ └───tests
│ test_main.py
│
├───policy
│ glue-job-policy.json
│
│ main.tf
Do I need to follow this exactly project structure in order to work with terraglue?
No, you don't and that's one of the coolest terraglue features. You can take any Terraform project in any structure and call terraglue without any worries.
You will just need to pay attention to the module variables you pass during the call. To see a full list of all acceptable variables, check the Variables section. The Validations section is also a good page to read in order to be aware of some input variable conditions based on specific scenarios.
If you need more information about the structure of a Terraform project you can check the official Hashicorp documentation about it.
Collecting Terraform Data Sources¶
Once we structured the Terraform project, let's start by collecting some Terraform data sources that will be used along the project. Terraform data sources can improve the development of a Terraform project in a lot of aspects. In the end, this is not a required step, but it can be considered as a good practice according to which resources will be declared and which configurations will be applied.
So, let's take our main.tf file and get the three Terraform data sources stated balow:
- A aws_caller_identity data source to extract the user account id
- A aws_region data source to get the target AWS region
- A aws_kms_key data source to get a KMS key by its alias (assuming that there is a KMS key alias in the target AWS account)
Collecting Terraform data sources
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
And now we are ready to call the terraglue module and start customizing it through its variables.
Configuring Terraglue¶
In order to provide a clear vision for users, this demo will be divided into multiple records in different sections. The idea is to delivery a step by step guide showing all customizations applied to terraglue module call using the following topics:
- Calling the module from GitHub
- Setting up IAM variables
- Setting up KMS variables
- Setting up S3 scripts location
- Setting up the Glue job
- Setting up job arguments
By following all demos from each topic, users will be able to fully understand terraglue and all its different ways to deploy Glue jobs.
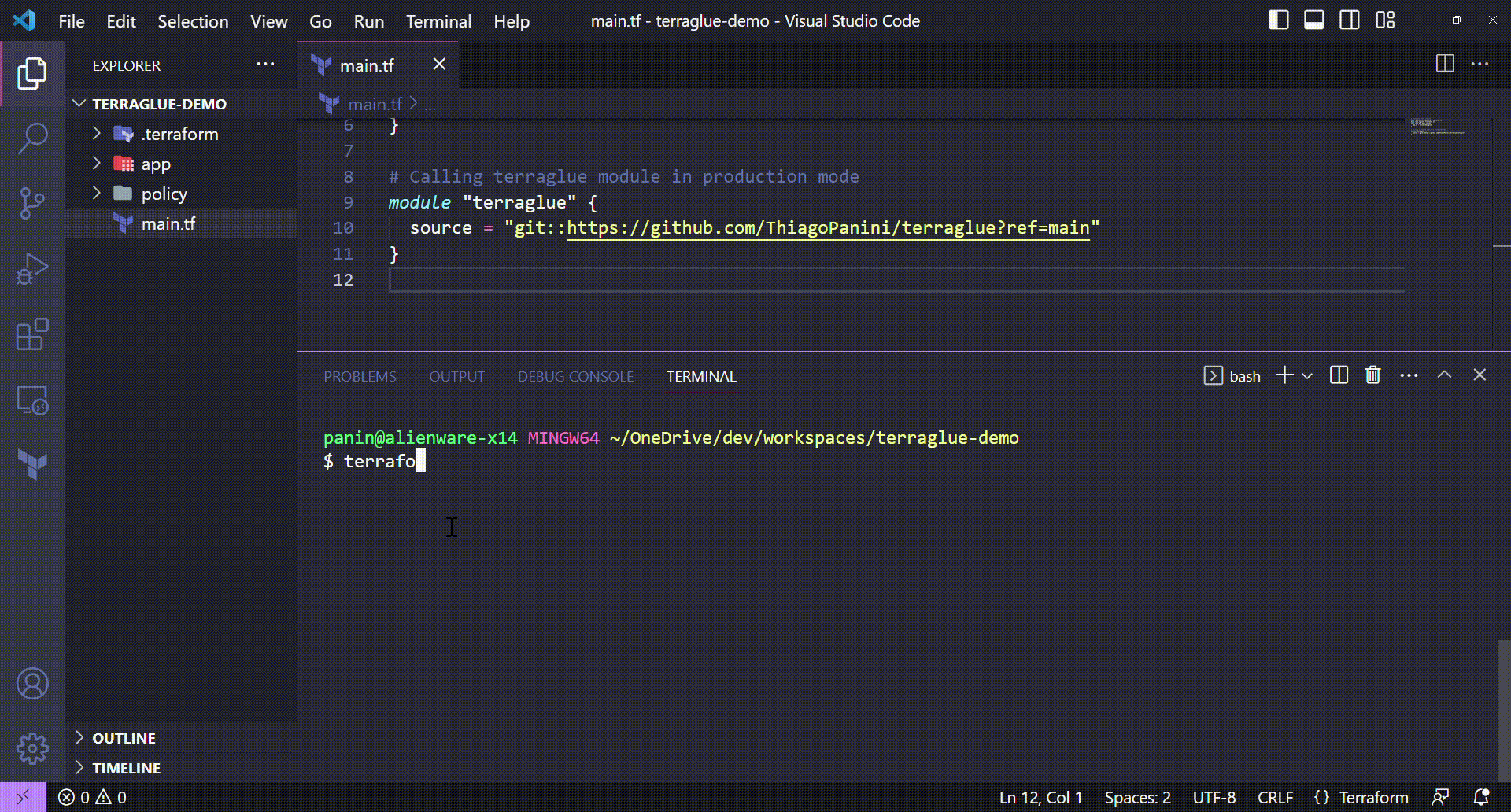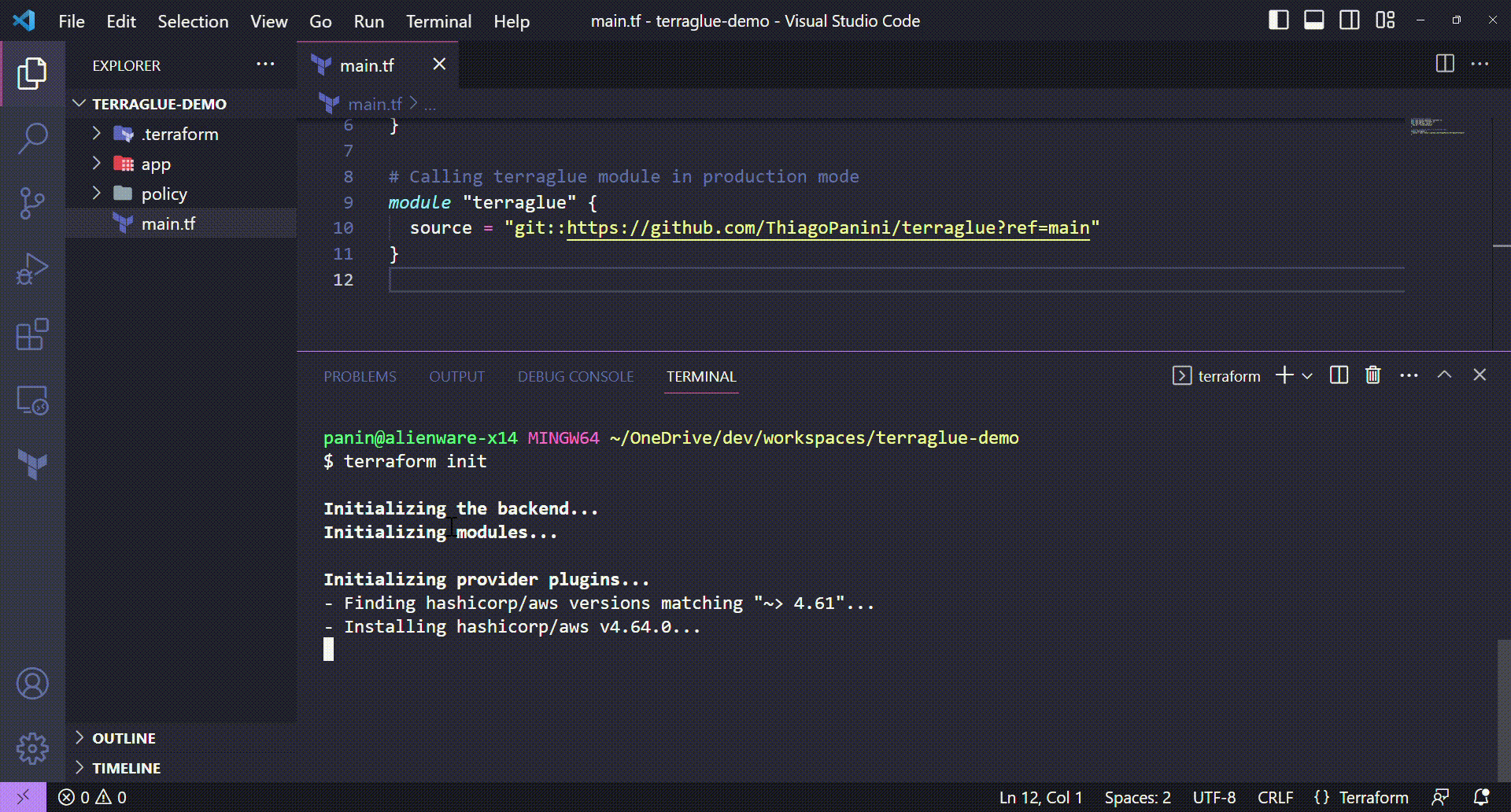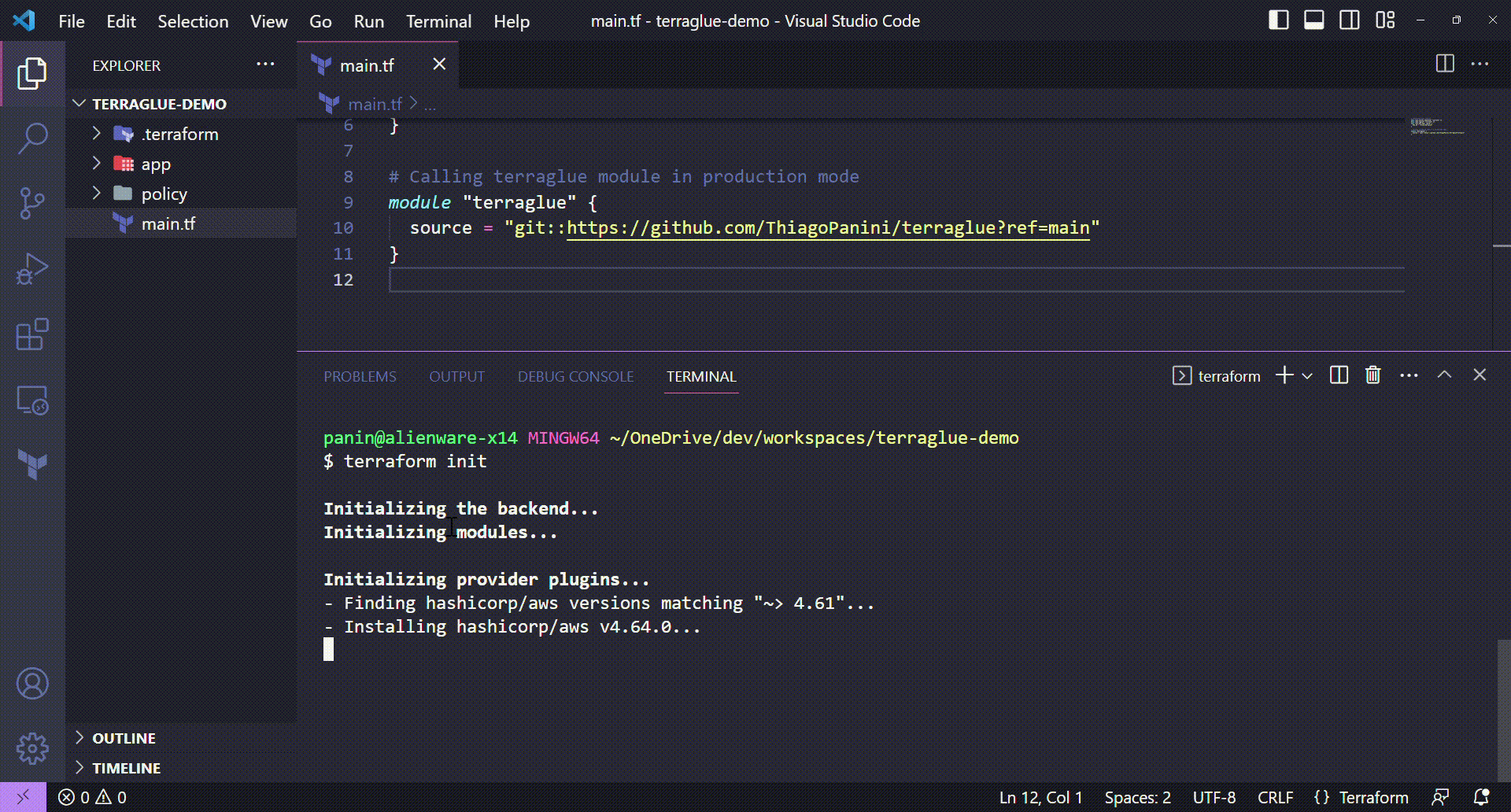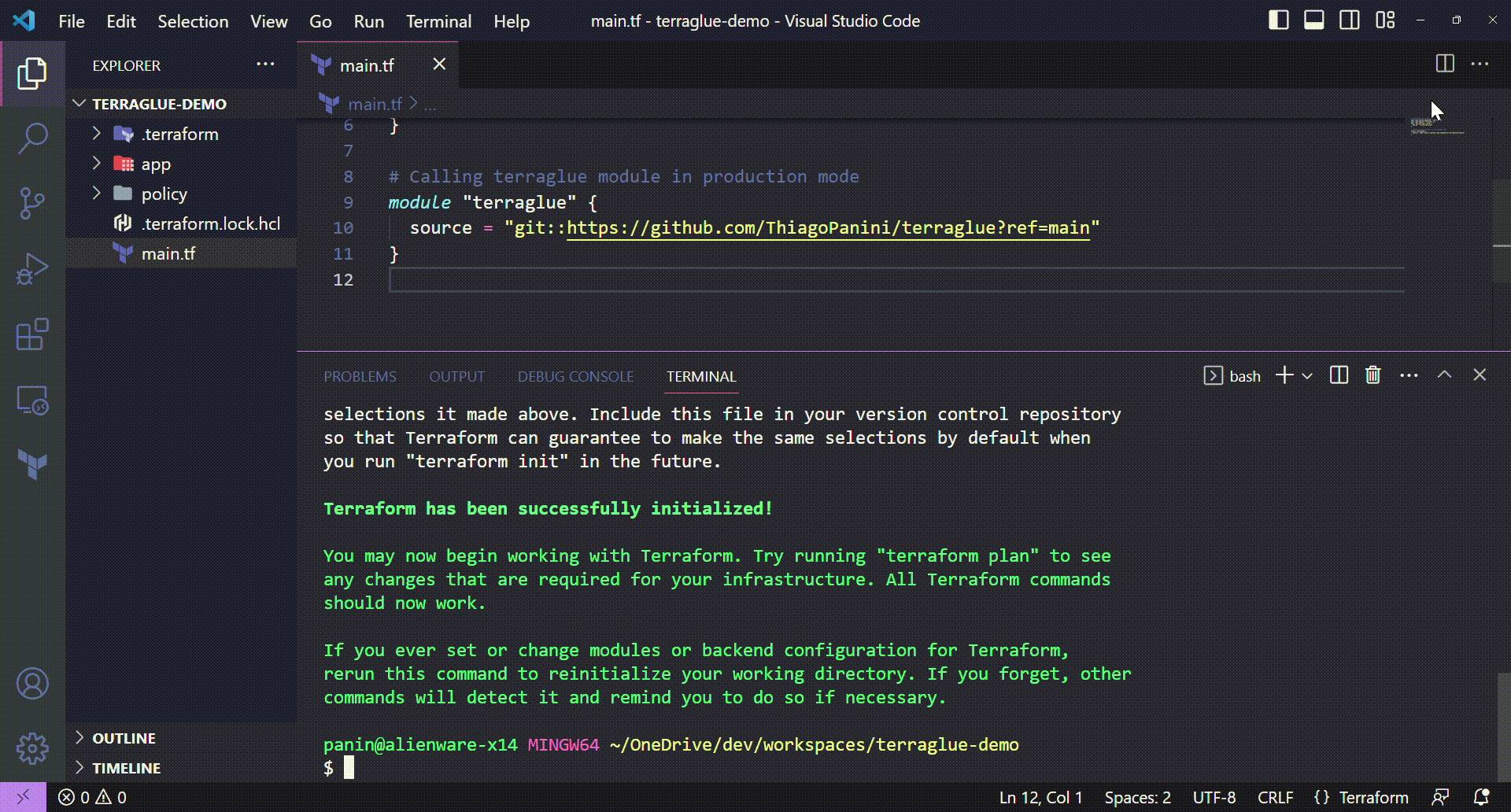
Calling The Source Module¶
This section is all about showing how to call the terraglue module directly from GitHub.
Calling the terraglue module directly from GitHub
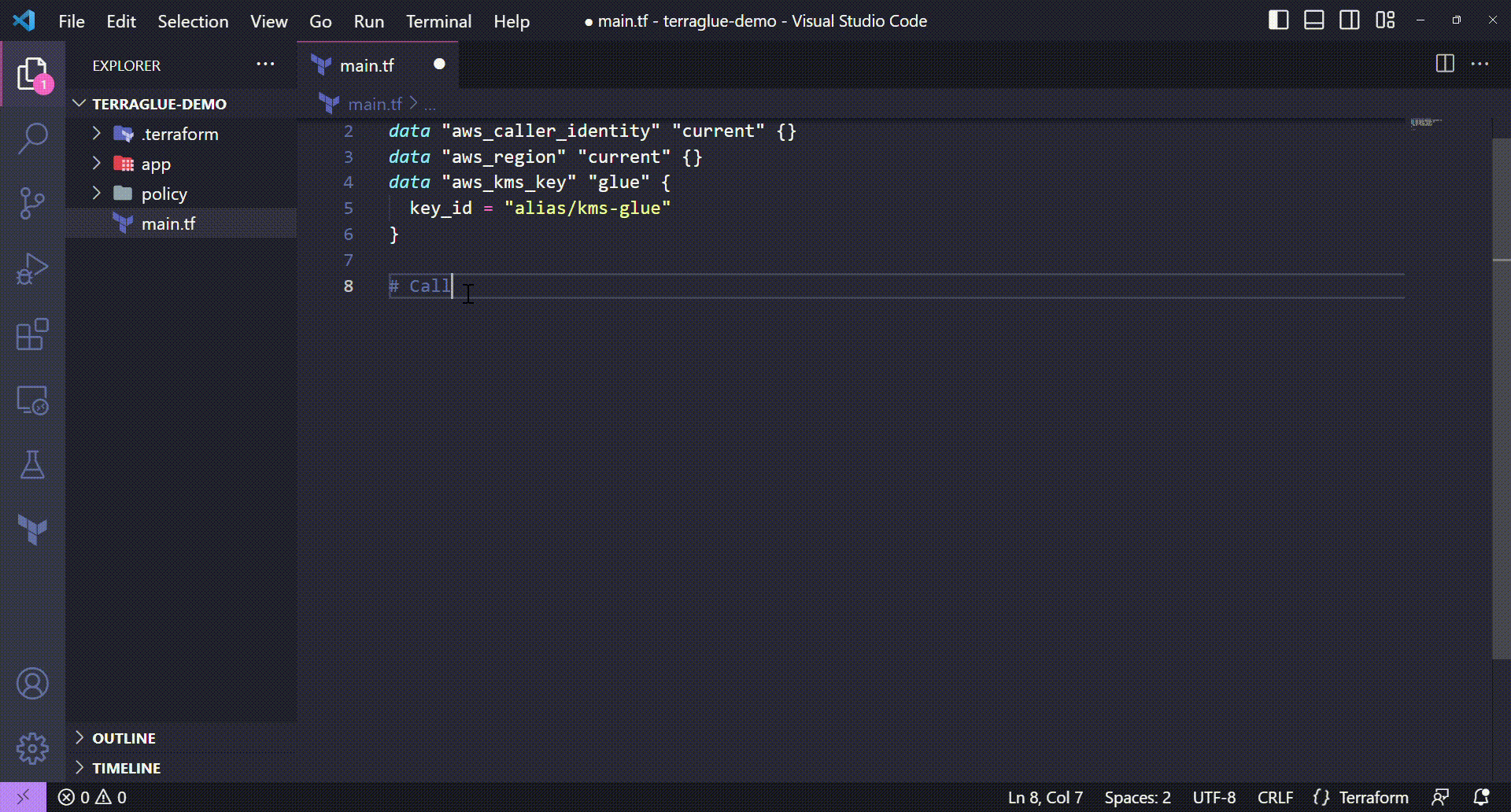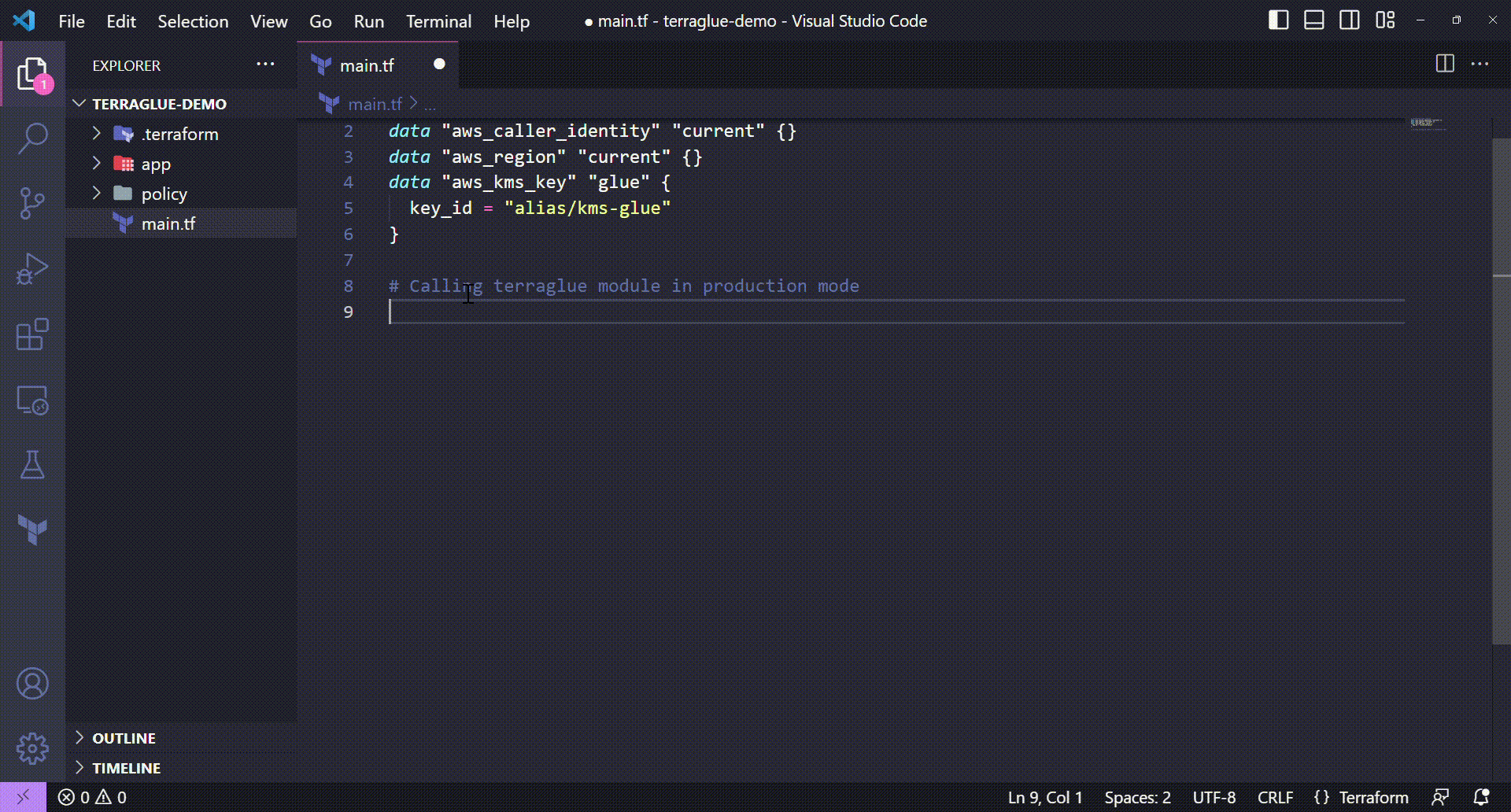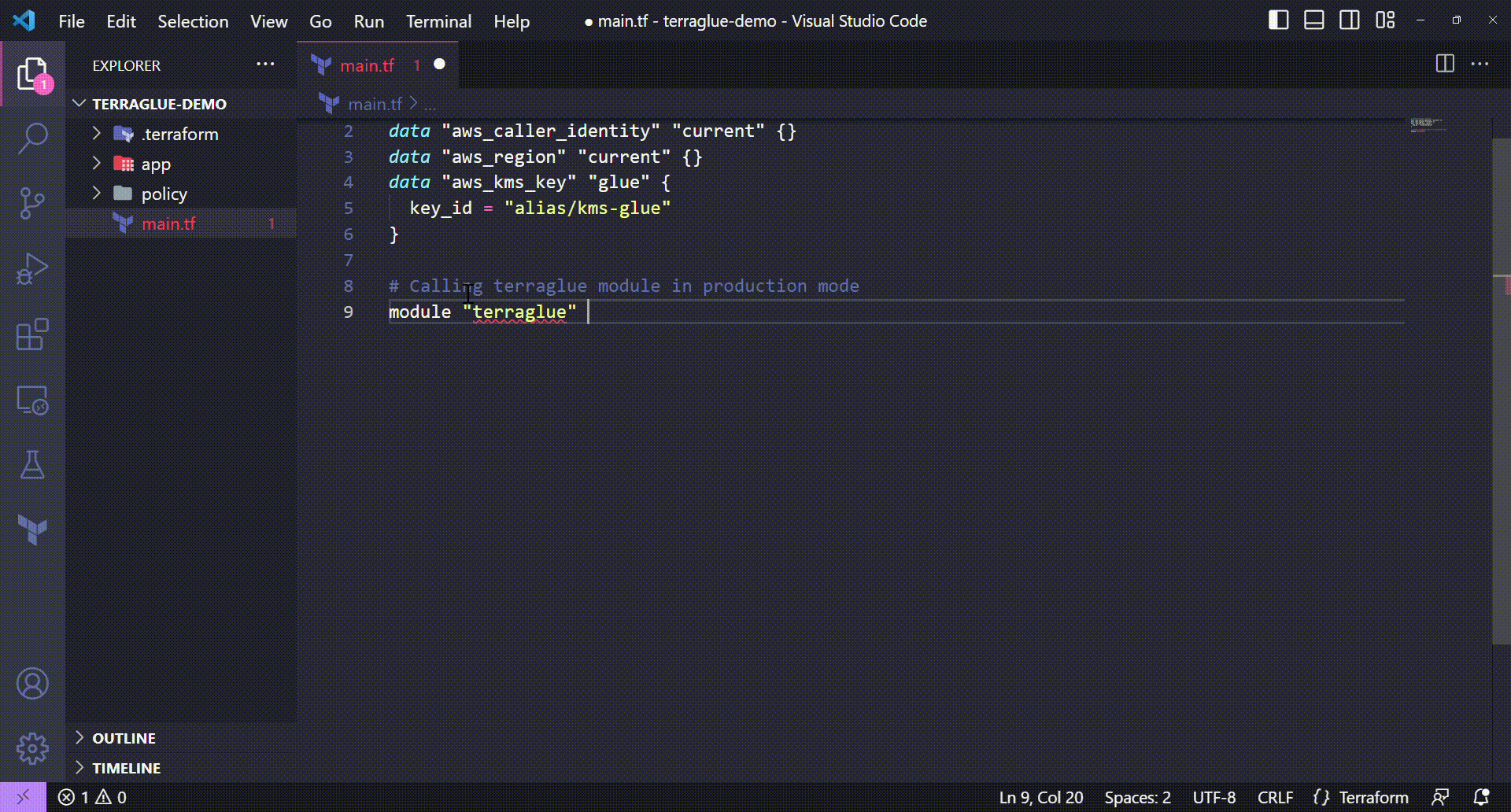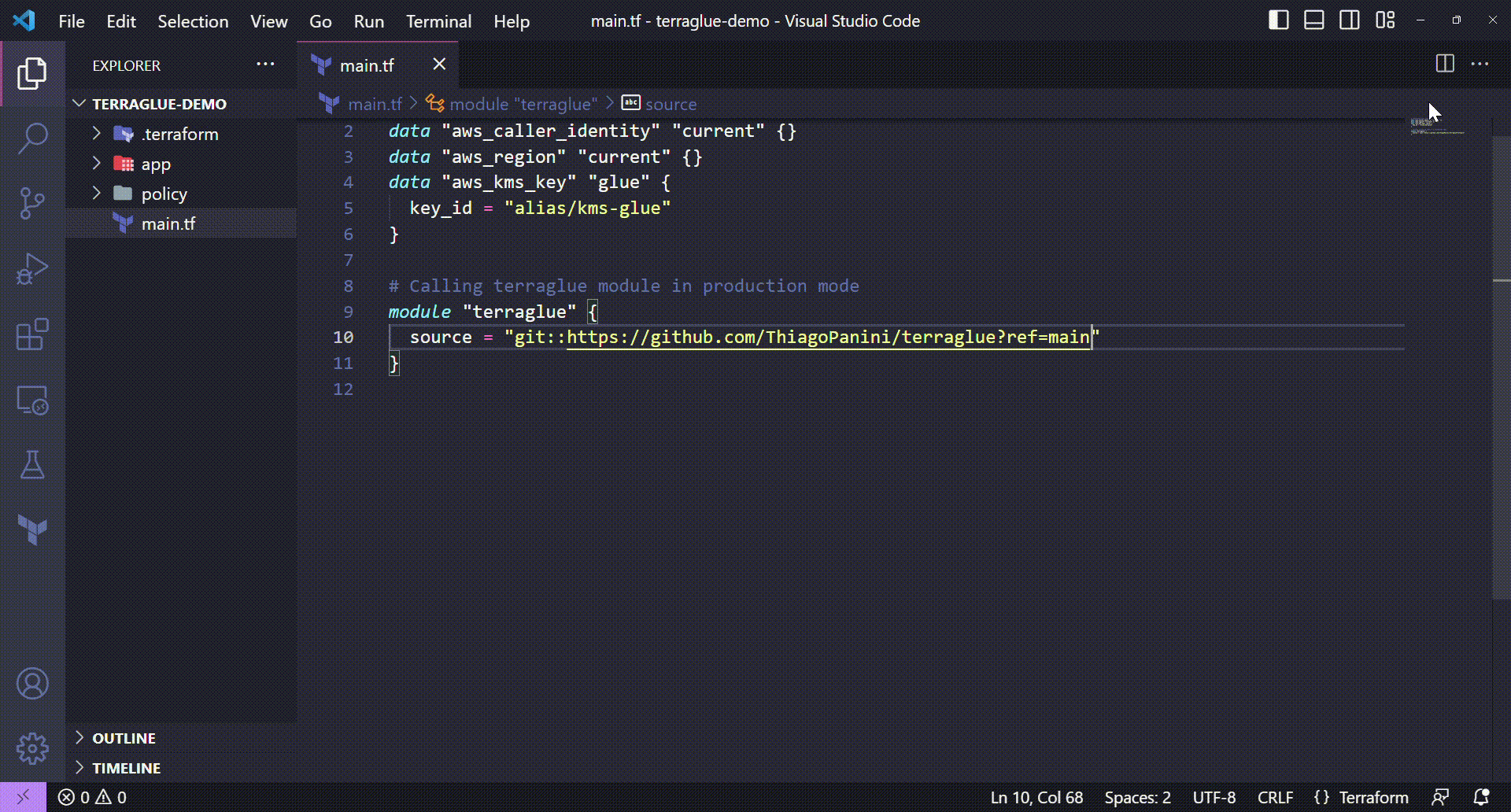
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
# Calling terraglue module in production mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
}
There are more things to setup before deploying terraglue
As stated before in this documentation, terraglue has a lot of variables and most of them has default values. But still there are some things to configure and customize before deploying it in a target AWS account.
Optionally, users can initialize the terraglue module declared through terraform init command in order to get a simple but huge feature: the autocomplete text in variable names from the module. This can make things a lot easier whe configuring terraglue in the next sections.
Setting Up IAM Variables¶
So, let's start customizing terraglue by setting some IAM variables to guide how the module will handle the IAM role needed to be assumed by the Glue job.
For this demo, let's set the following configurations:
- Inform terraglue that we want to create an IAM role in this project
- Inform terraglue that the IAM policies that will be part of this role are located in the
policy/folder - Inform terraglue the name of the IAM role to be created
Setting up IAM variables on terraglue
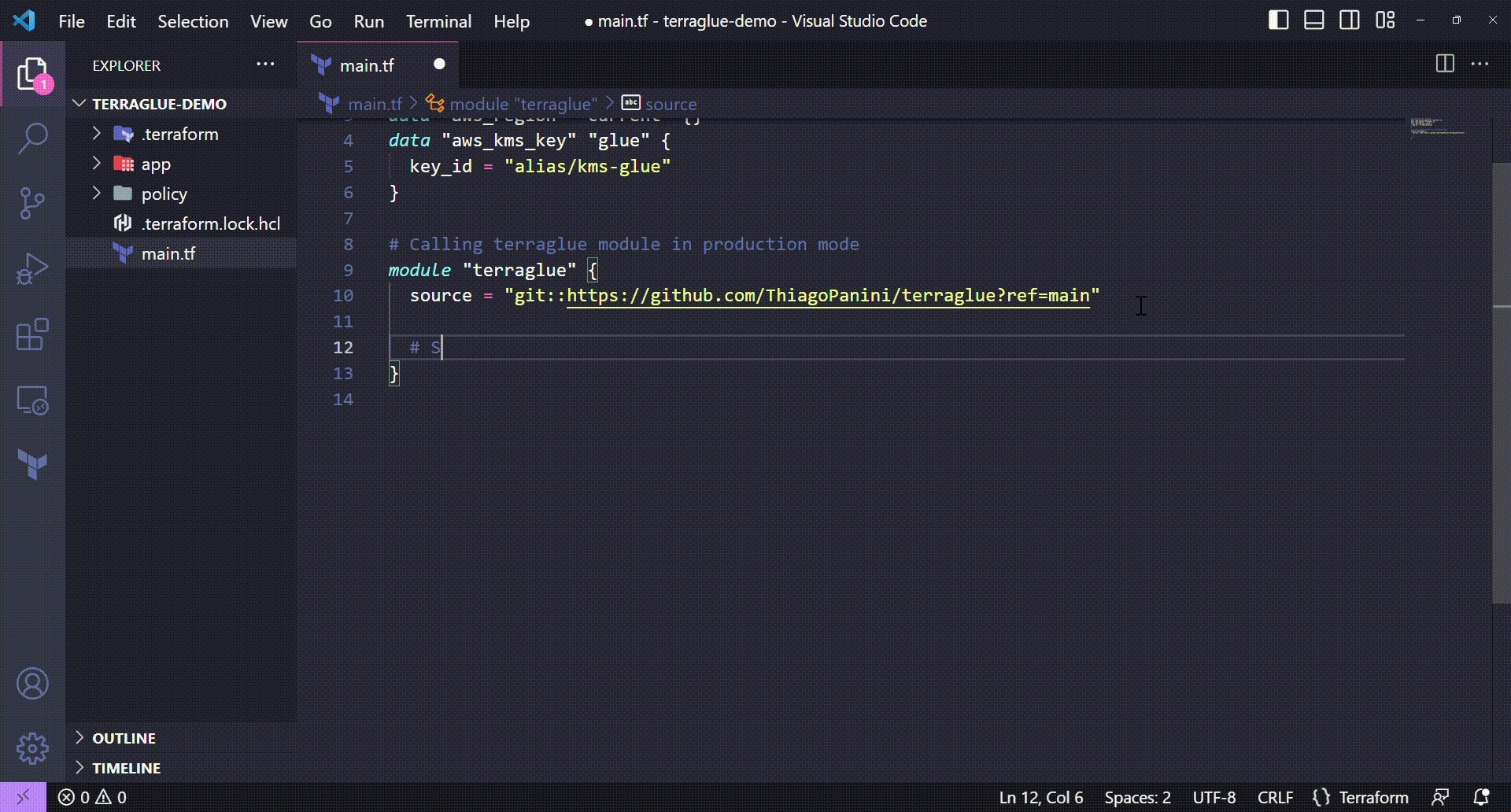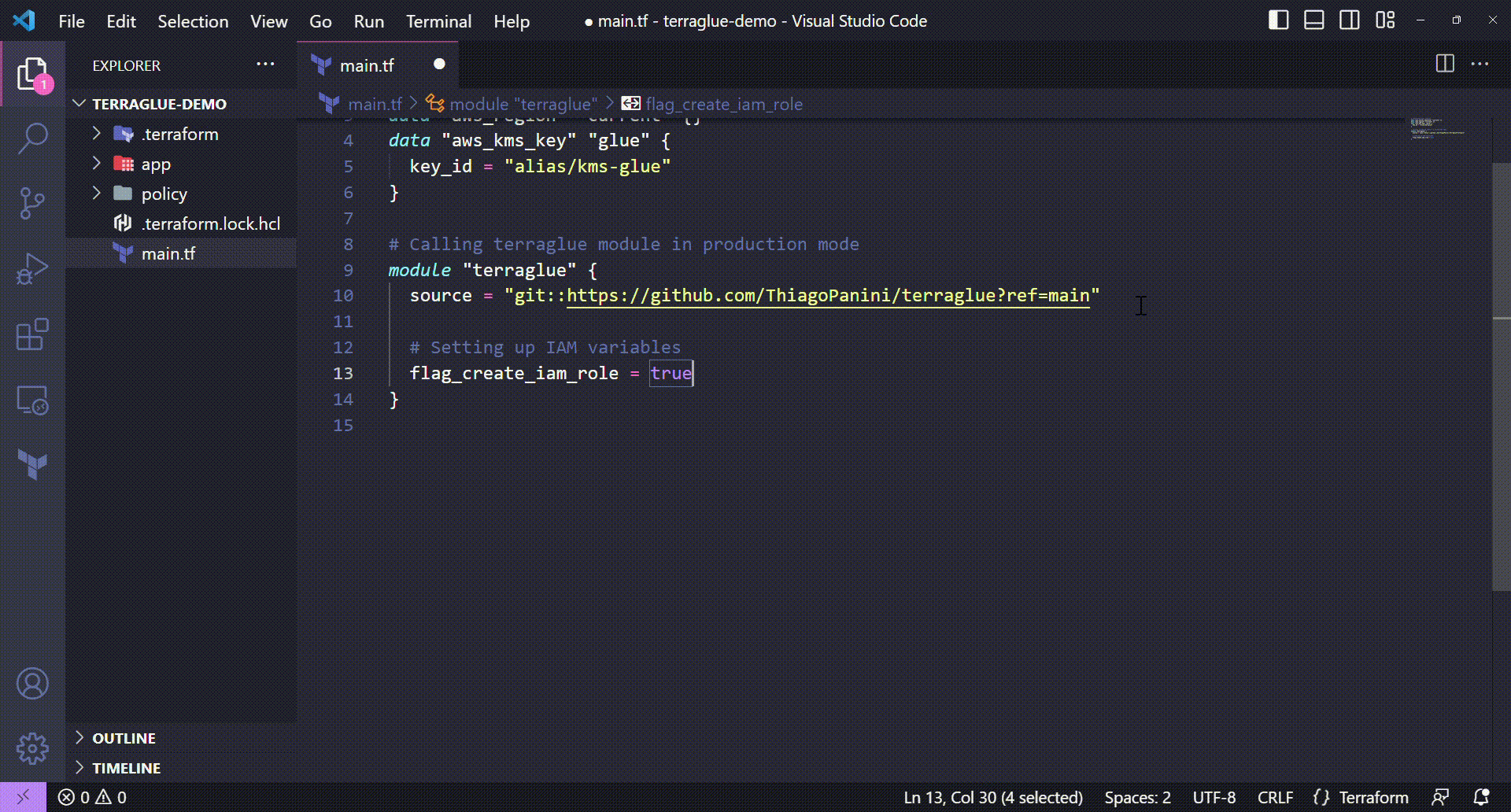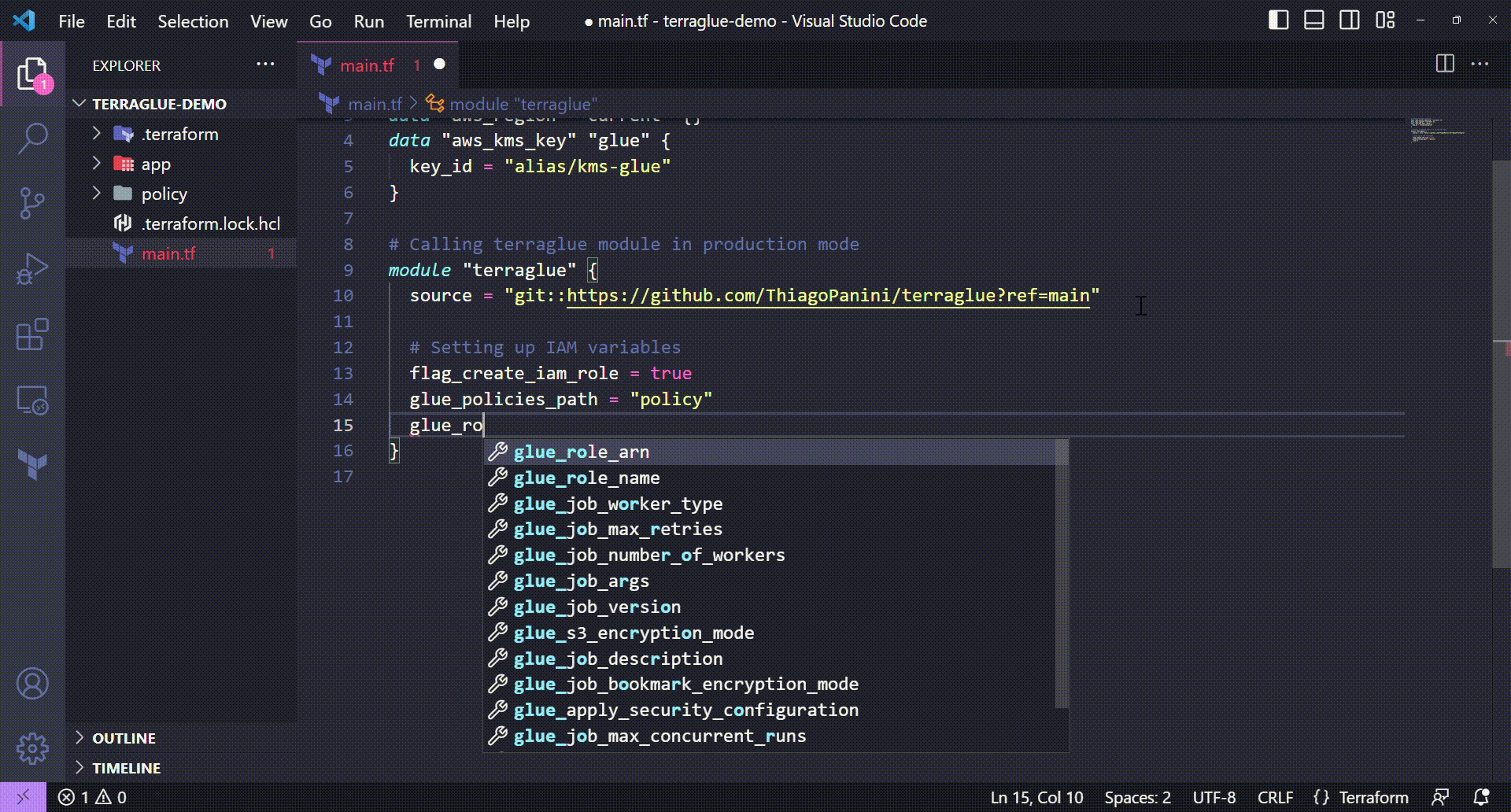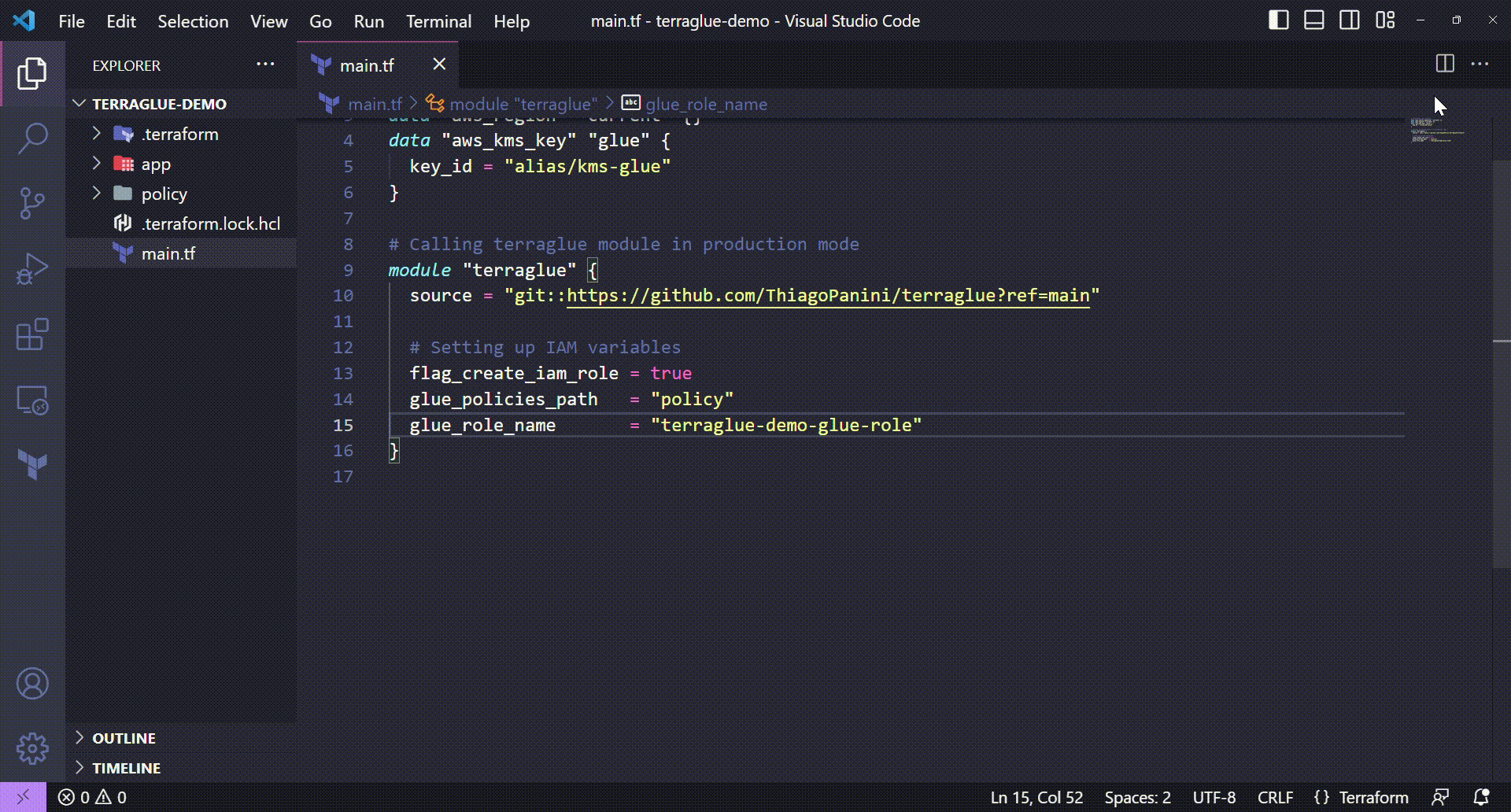
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
# Calling terraglue module in production mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
# Setting up IAM variables
flag_create_iam_role = true
glue_policies_path = "policy"
glue_role_name = "terraglue-demo-glue-role"
}
To see more about all IAM configuration variables available on terraglue, check this link.
Setting Up KMS Variables¶
Well, the next step in this demo will handle KMS key configuration that affects our Glue job. In this project, we will apply the following KMS configurations on terraglue:
- Inform terraglue to now create a KMS key during project deploy (we sill use an existing key)
- Inform terraglue the ARN of the existing KMS key (collected from the
aws_kms_keyTerraform data source declared at the beginning of the project)
Setting up KMS variables on terraglue
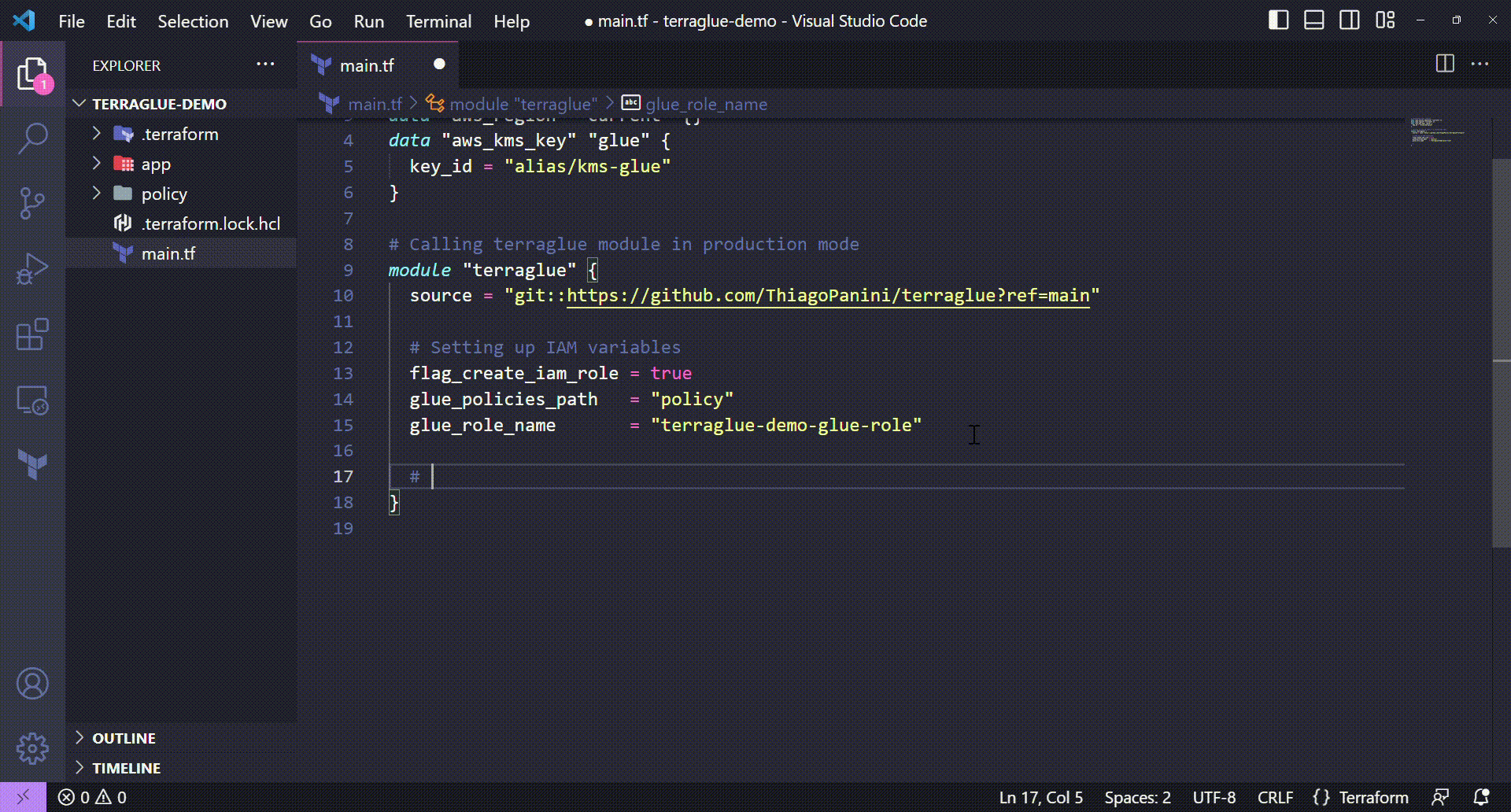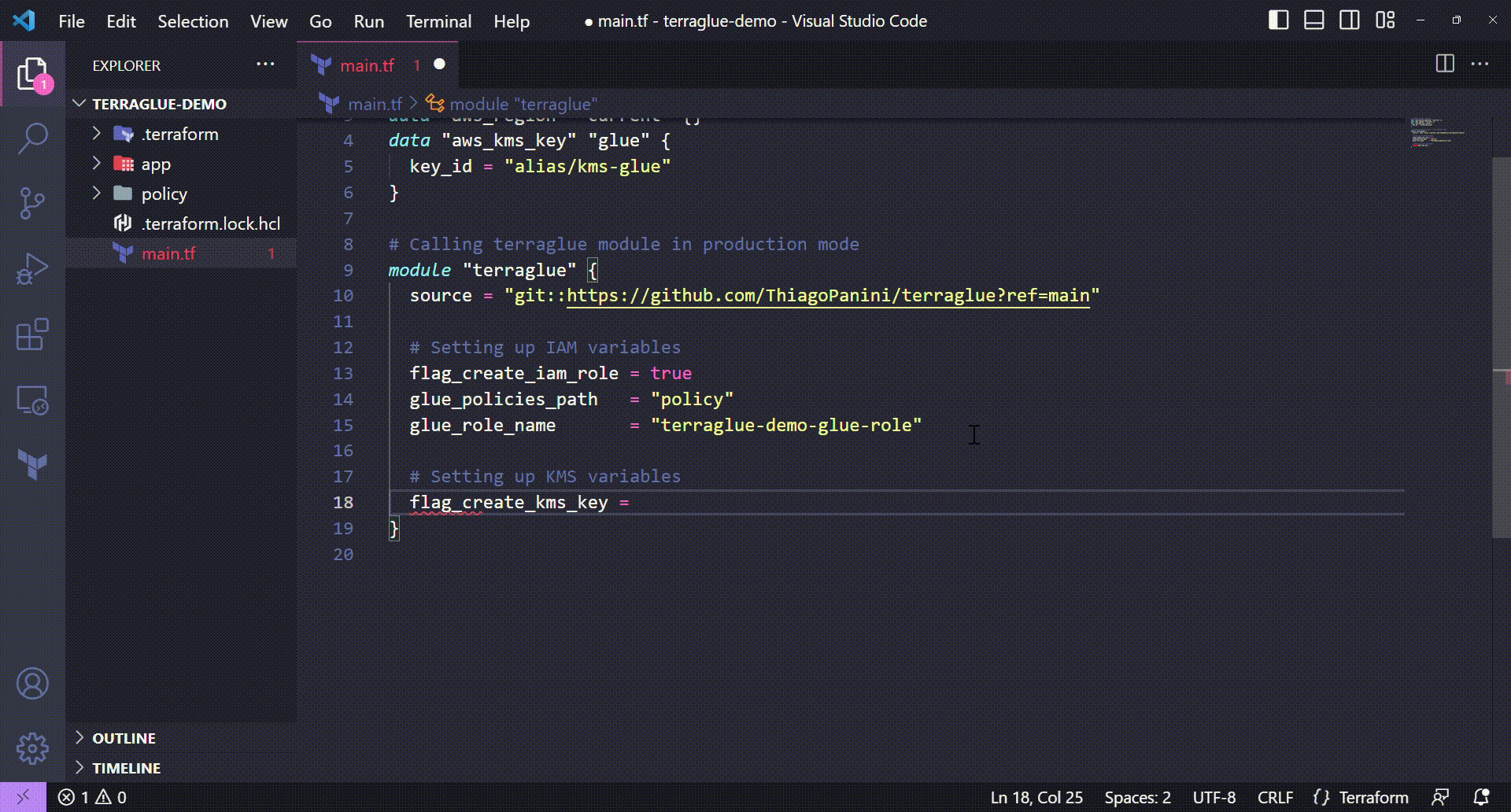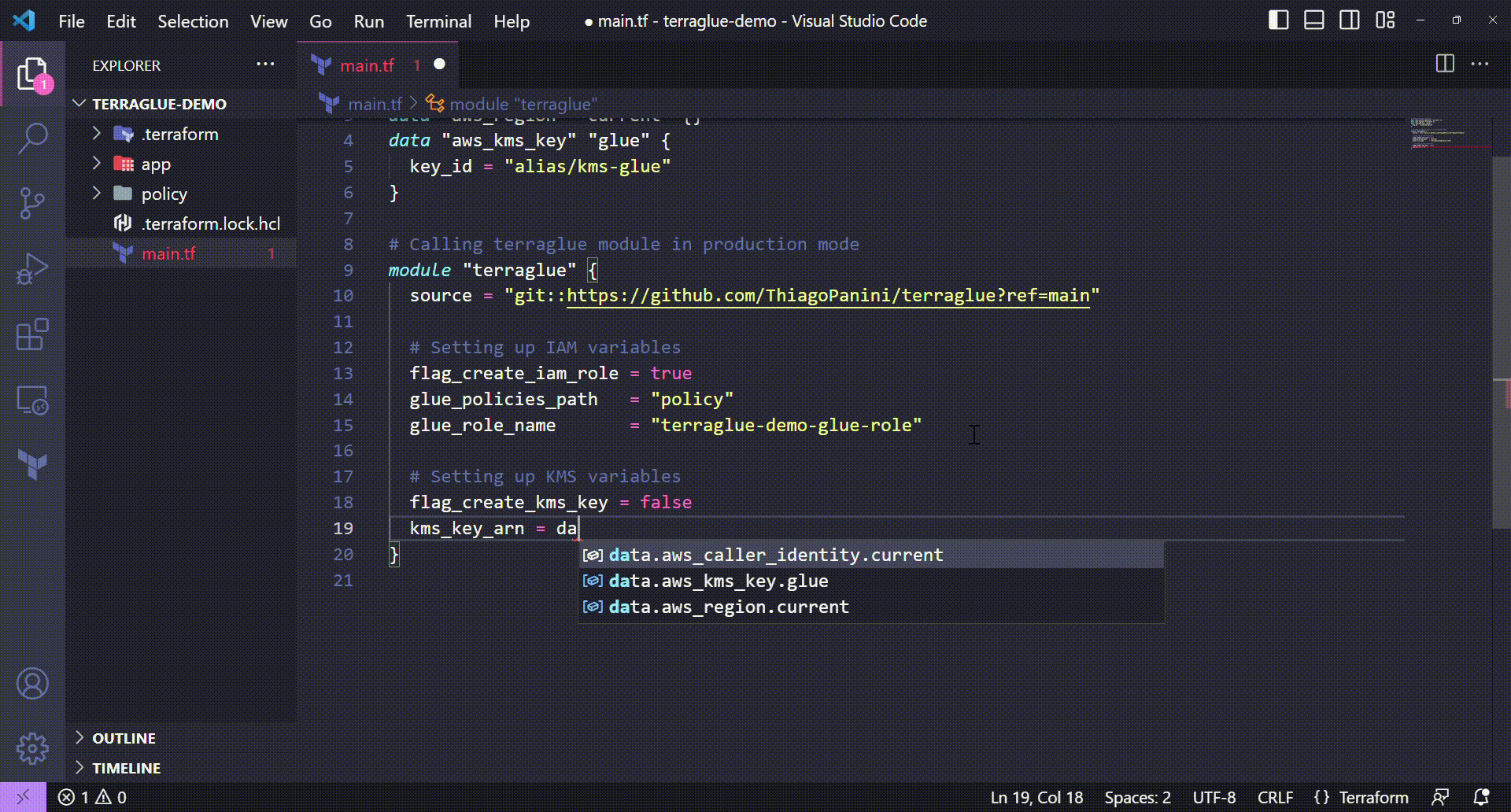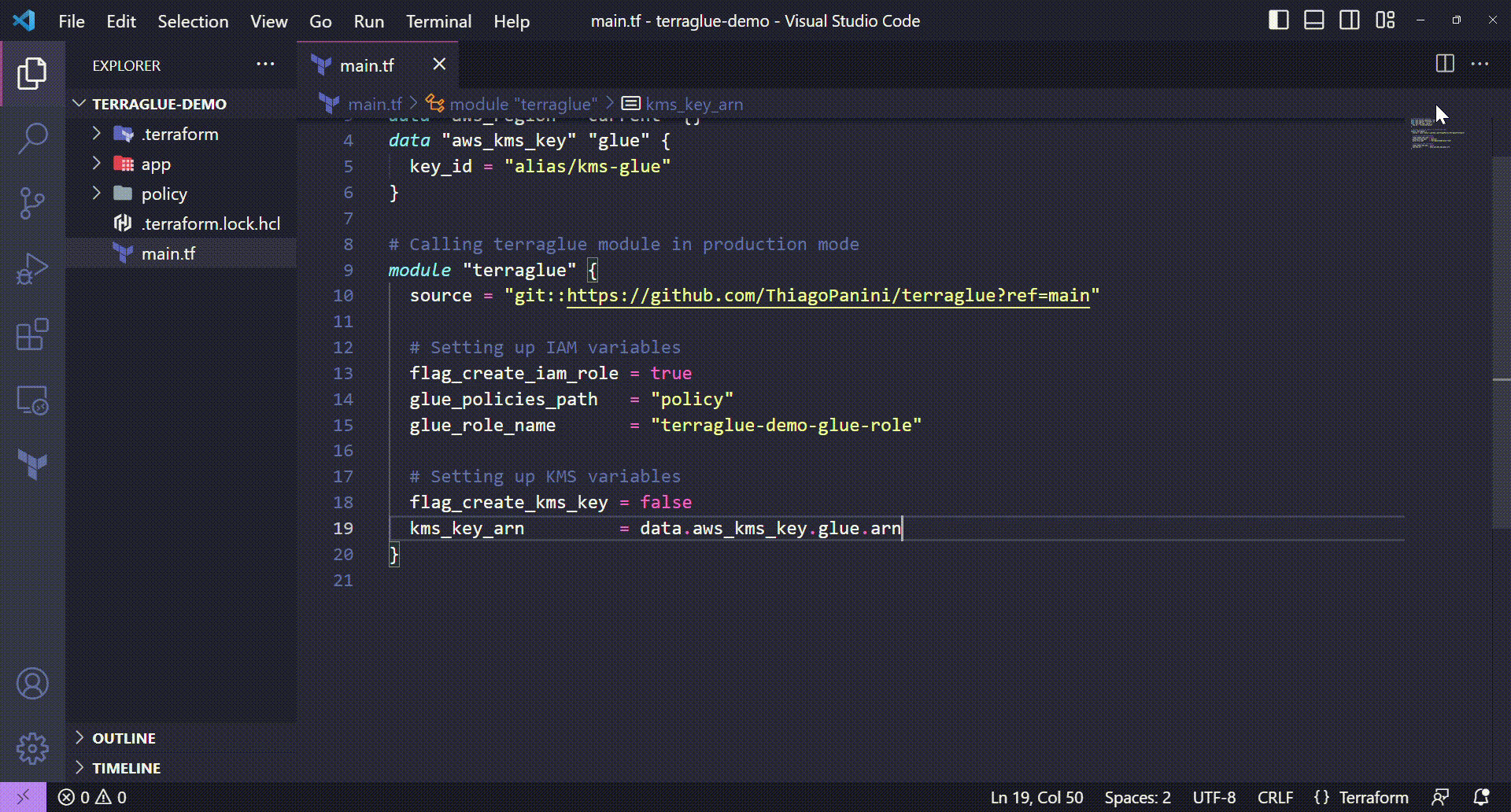
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
# Calling terraglue module in production mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
# Setting up IAM variables
flag_create_iam_role = true
glue_policies_path = "policy"
glue_role_name = "terraglue-demo-glue-role"
# Setting up KMS variables
flag_create_kms_key = false
kms_key_arn = data.aws_kms_key.glue.arn
}
To see more about all KMS configuration variables available on terraglue, check this link.
Setting Up S3 Scripts Location¶
After the successfully configuration of IAM and KMS variables, it's time to set up a bucket reference which will be considered by terraglue to store all Glue scripts files in the project.
Basically, this is the step where users provide a bucket name to host the files located in the app/ project folder in order to be used in the Glue job.
In this demo, we will use the aws_caller_identity and aws_region data sources collected at the beginning of the project to build a bucket name without hard coding informations such as account ID and AWS region.
Setting up a s3 bucket name to store scripts files
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
# Calling terraglue module in production mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
# Setting up IAM variables
flag_create_iam_role = true
glue_policies_path = "policy"
glue_role_name = "terraglue-demo-glue-role"
# Setting up KMS variables
flag_create_kms_key = false
kms_key_arn = data.aws_kms_key.glue.arn
# Setting up S3 scripts location
glue_scripts_bucket_name = "datadelivery-glue-assets-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.name}"
}
To see more about all S3 configuration variables available on terraglue, check this link.
Setting Up A Glue Job¶
And here we probably have the most important configuration set of a terraglue module call: the Glue job set up.
The idea with this variables block is:
- Inform terraglue to associate a name to the Glue job
- Inform terraglue to associate a description to the Glue job
- Inform terraglue to use G.1X workers
- Inform terraglue to use 5 workers
Setting up a Glue job
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
# Calling terraglue module in production mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
# Setting up IAM variables
flag_create_iam_role = true
glue_policies_path = "policy"
glue_role_name = "terraglue-demo-glue-role"
# Setting up KMS variables
flag_create_kms_key = false
kms_key_arn = data.aws_kms_key.glue.arn
# Setting up S3 scripts location
glue_scripts_bucket_name = "datadelivery-glue-assets-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.name}"
# Setting up Glue
glue_job_name = "terraglue-sample-job"
glue_job_description = "A sample job using terraglue with production mode"
glue_job_worker_type = "G.1X"
glue_job_number_of_workers = 5
}
To see more about all Glue configuration variables available on terraglue, check this link.
Setting Up Job Arguments¶
And finally, it's important to show how users can input their own Glue job arguments on terraglue. In fact, it can be done through the glue_job_args module variable that accepts a map object with all user arguments in order to customize the Glue job.
The main key points about the job arguments declared in this demo are:
- Set
--job-bookmark-optionin order to disable job bookmarks from the job - Set
--additional-python-modulesin order to use the sparksnake Python package as an additional python module - Set
--extra-py-filesin order to add a utils.py file uploaded in this same project as an extra Python file to be used in the job
In this step, users are free to set all Glue acceptable arguments. A full list can be found in the AWS official documentation about job parameters.
Setting up Glue job arguments
💻 Terraform code:
# Collecting data sources
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
data "aws_kms_key" "glue" {
key_id = "alias/kms-glue"
}
# Calling terraglue module in production mode
module "terraglue" {
source = "git::https://github.com/ThiagoPanini/terraglue?ref=main"
# Setting up IAM variables
flag_create_iam_role = true
glue_policies_path = "policy"
glue_role_name = "terraglue-demo-glue-role"
# Setting up KMS variables
flag_create_kms_key = false
kms_key_arn = data.aws_kms_key.glue.arn
# Setting up S3 scripts location
glue_scripts_bucket_name = "datadelivery-glue-assets-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.name}"
# Setting up Glue
glue_job_name = "terraglue-sample-job"
glue_job_description = "A sample job using terraglue with production mode"
glue_job_worker_type = "G.1X"
glue_job_number_of_workers = 5
# Setting up job args
glue_job_args = {
"--job-language" = "python"
"--job-bookmark-option" = "job-bookmark-disable"
"--enable-metrics" = true
"--enable-continuous-cloudwatch-log" = true
"--enable-spark-ui" = true
"--encryption-type" = "sse-s3"
"--enable-glue-datacatalog" = true
"--enable-job-insights" = true
"--additional-python-modules" = "sparksnake"
"--extra-py-files" = "s3://datadelivery-glue-assets-${data.aws_caller_identity.current. account_id}-${data.aws_region.current.name}/jobs/ terraglue-sample-job/app/src/utils.py"
}
}
And with this subsection we reach the end of the demos related to terraglue module configuration.
Running Terraform Commands¶
After all this configuration journey, we now just need to plan and apply the deployment using the respective Terraform commands.
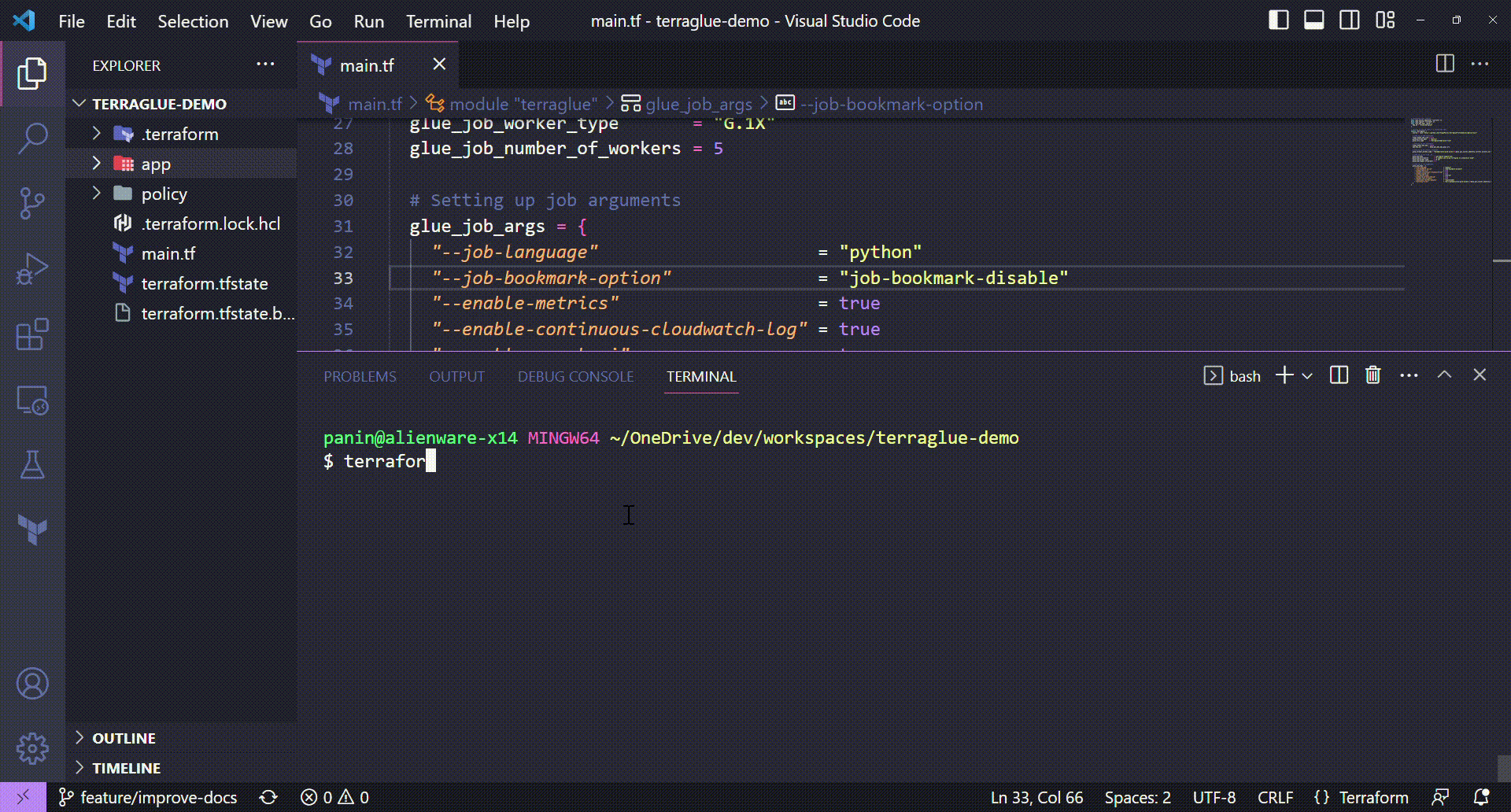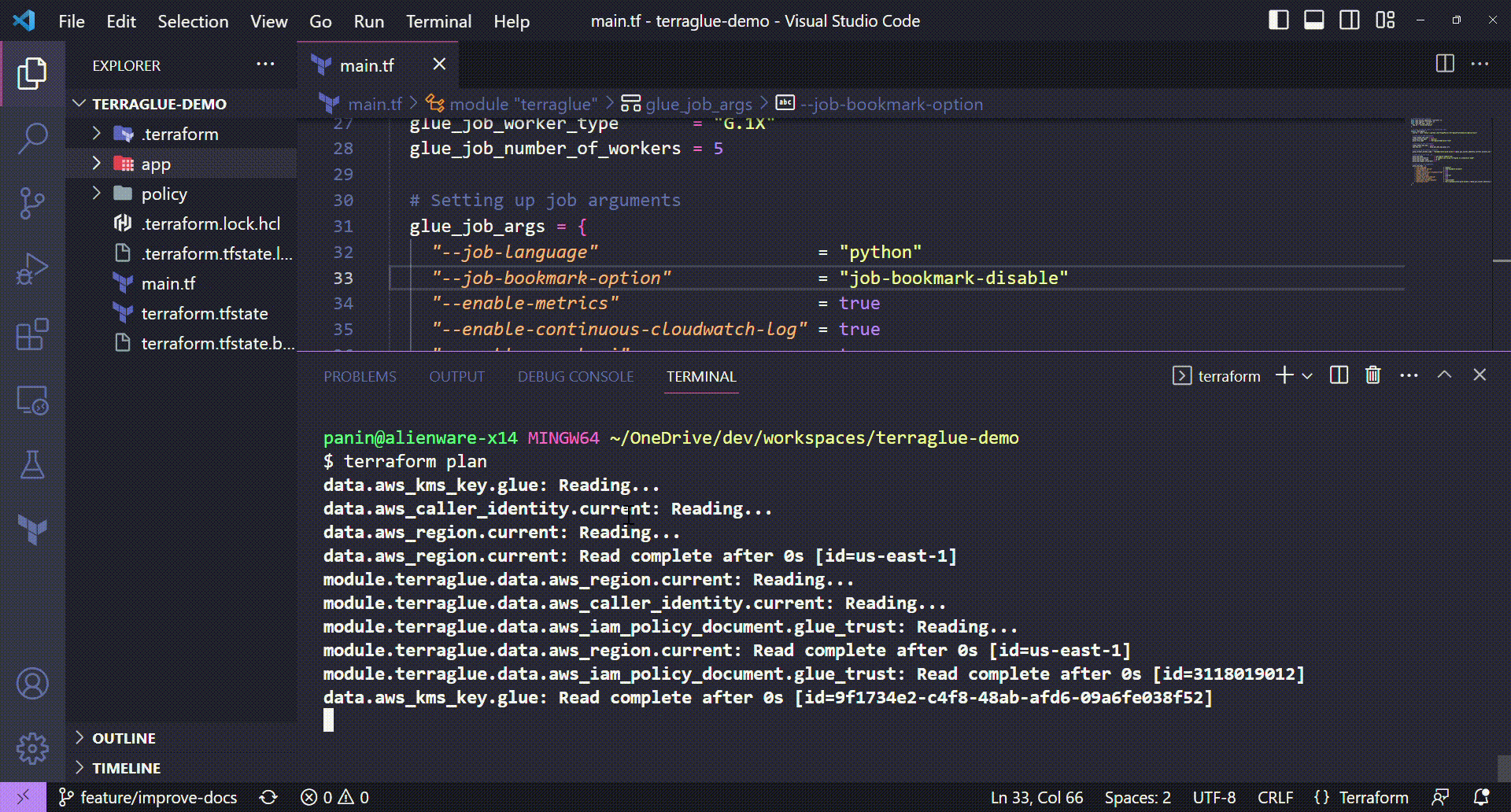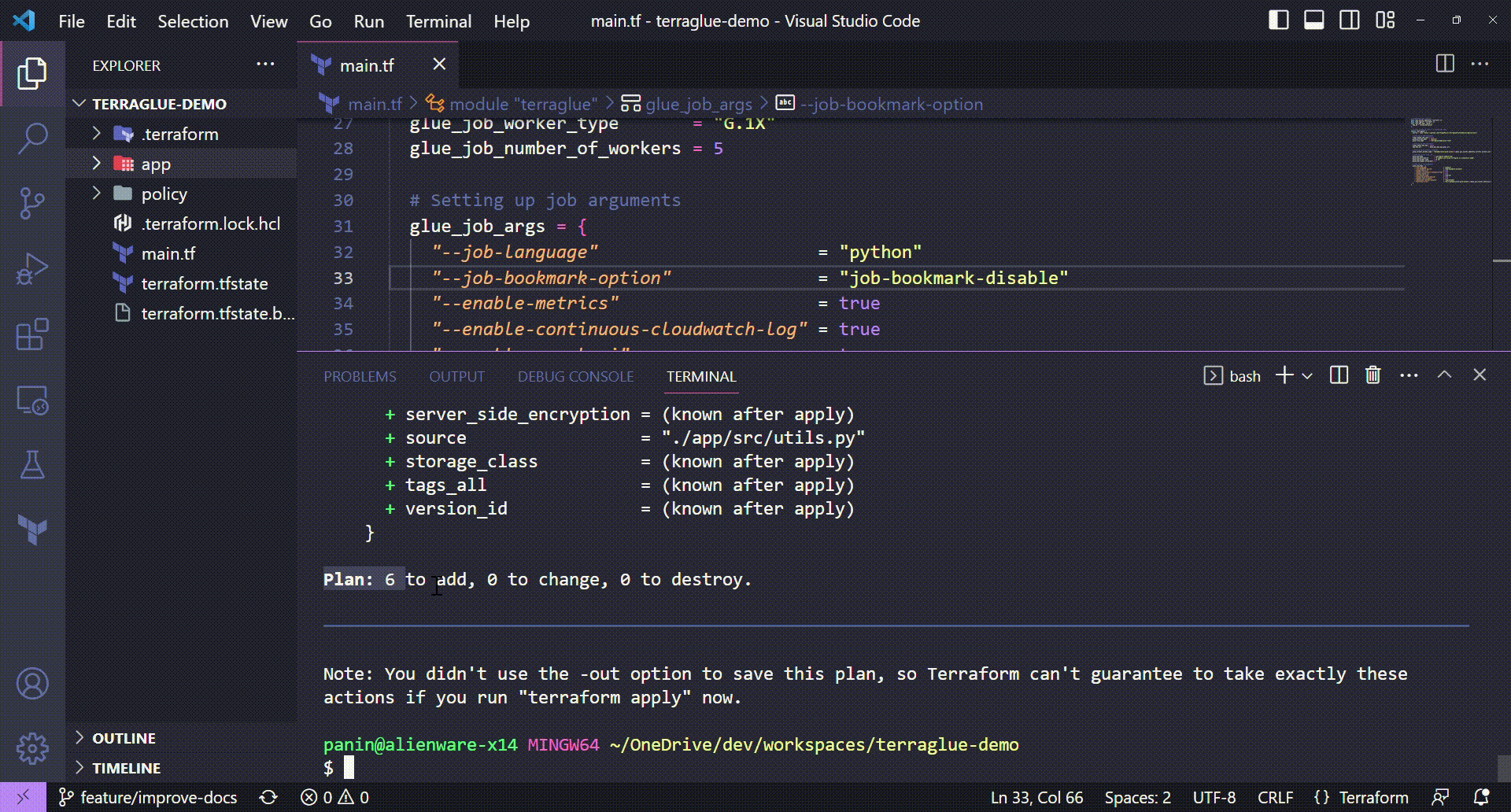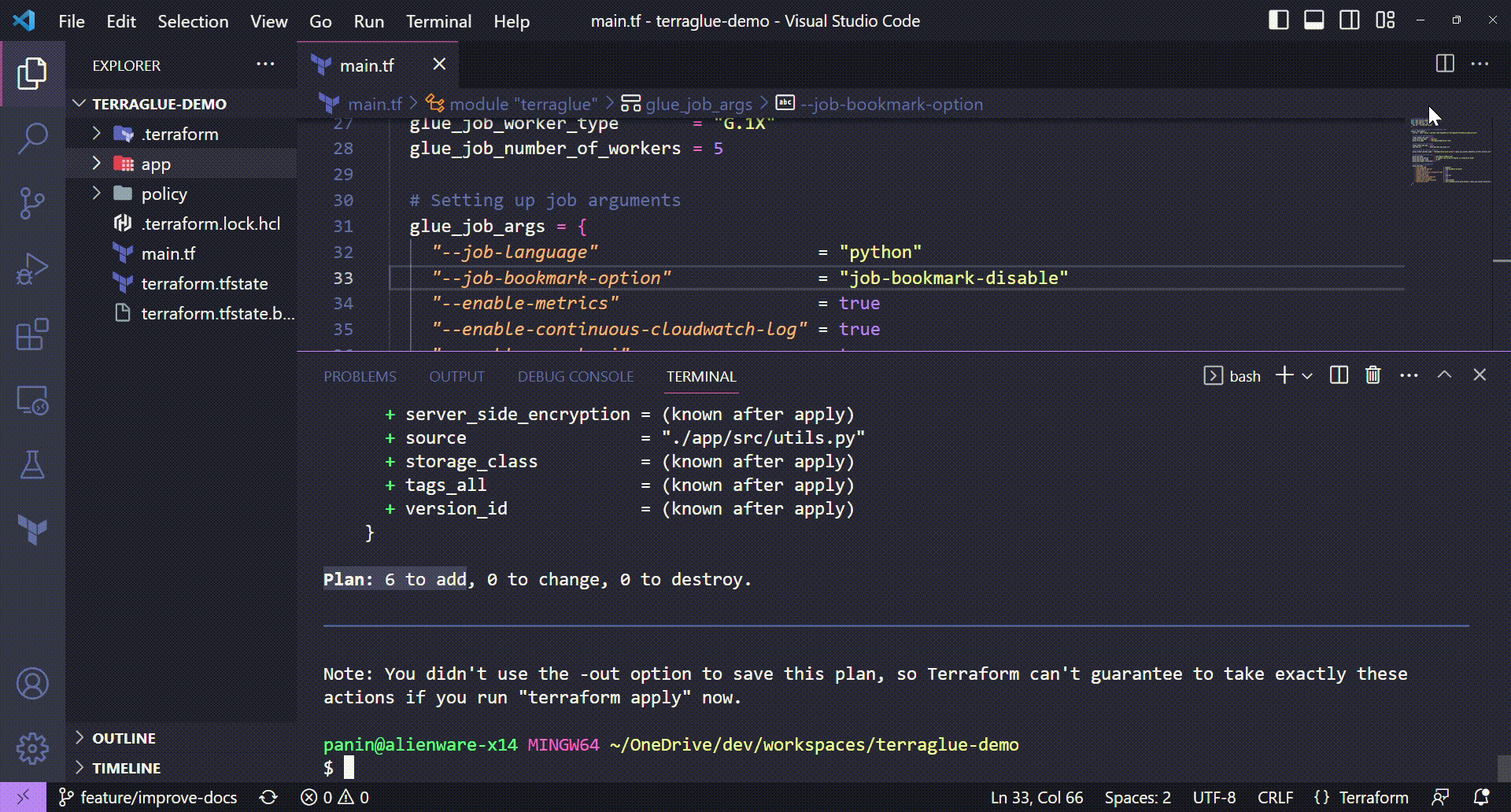
Terraform plan¶
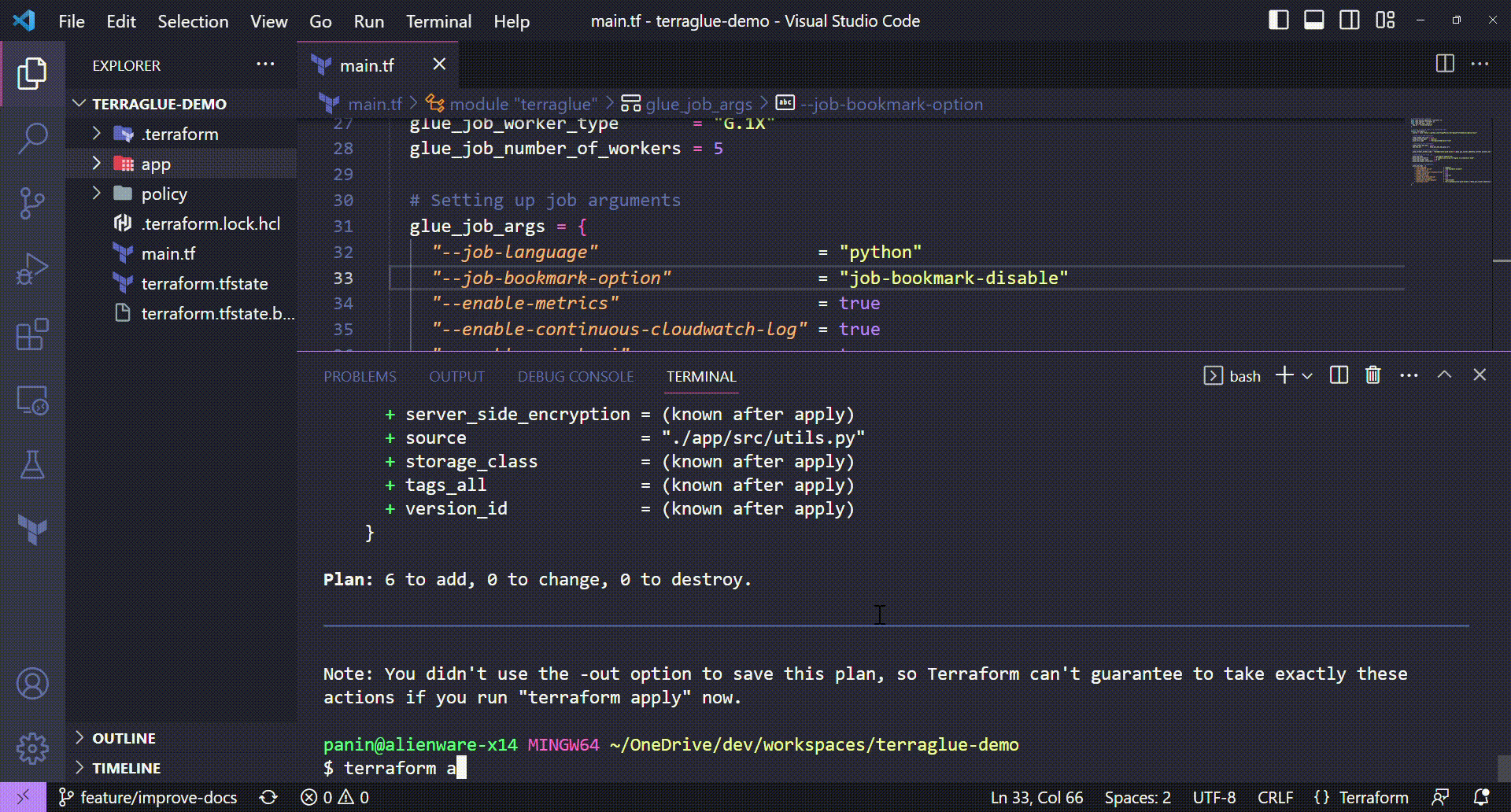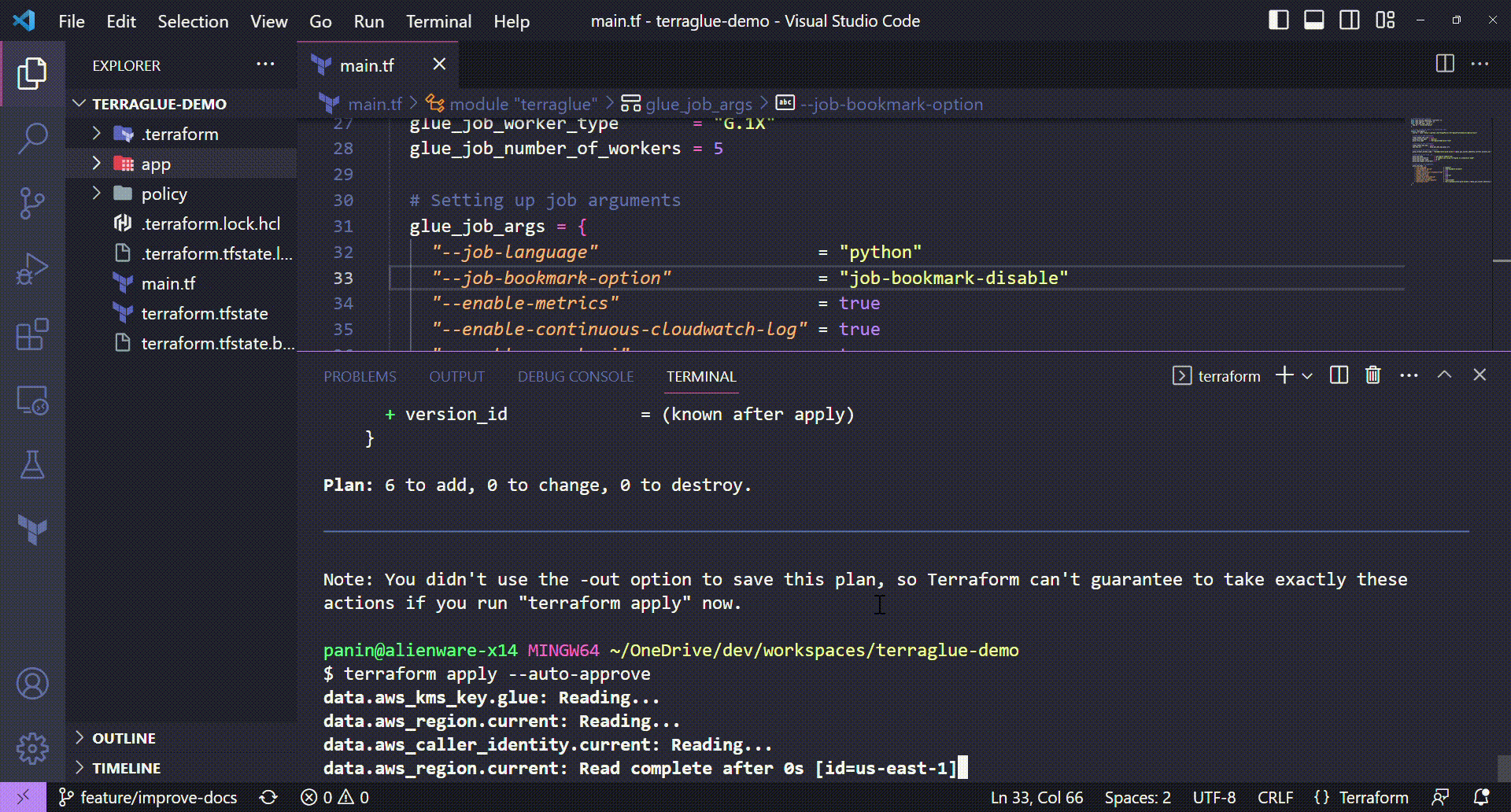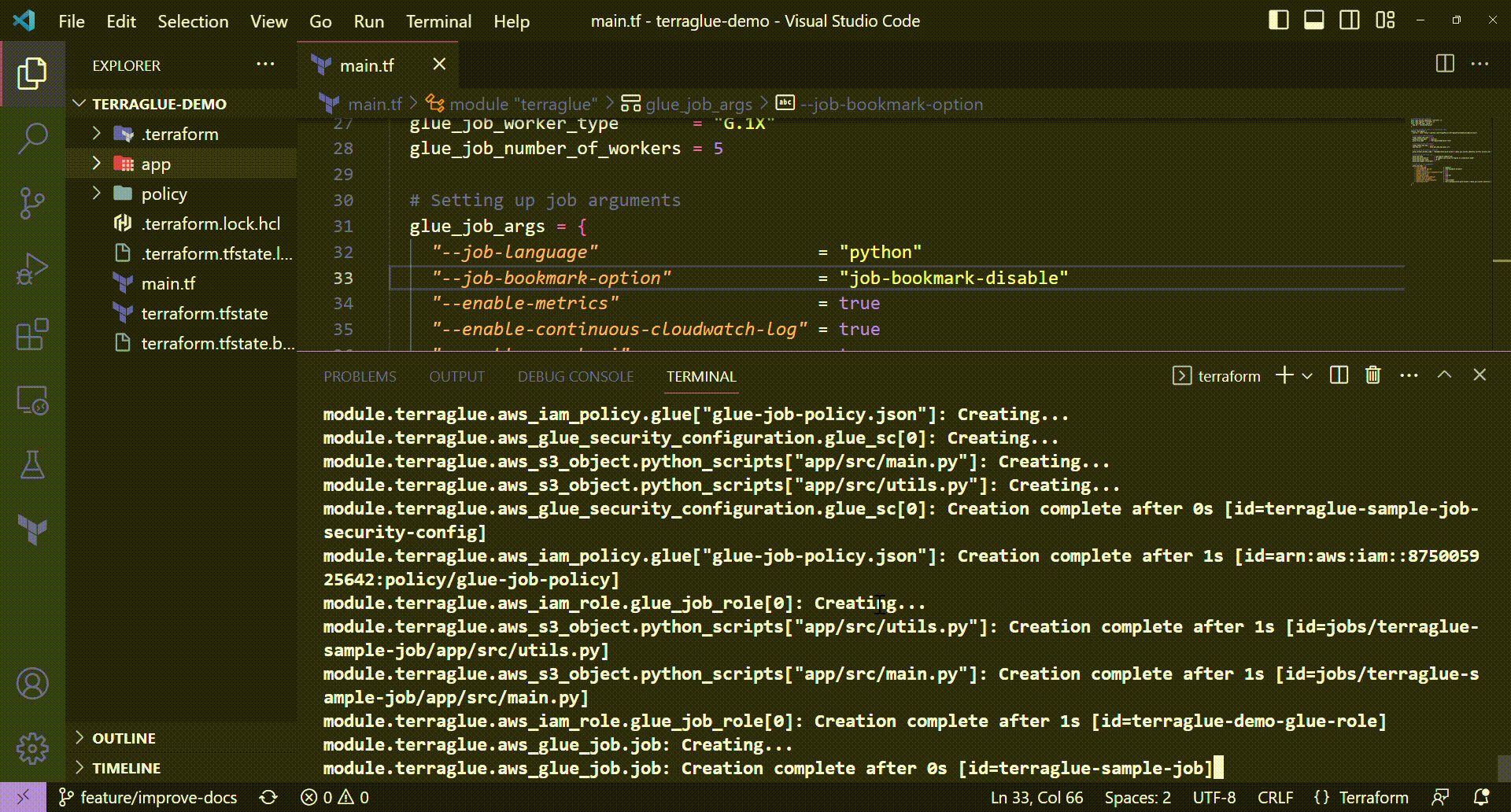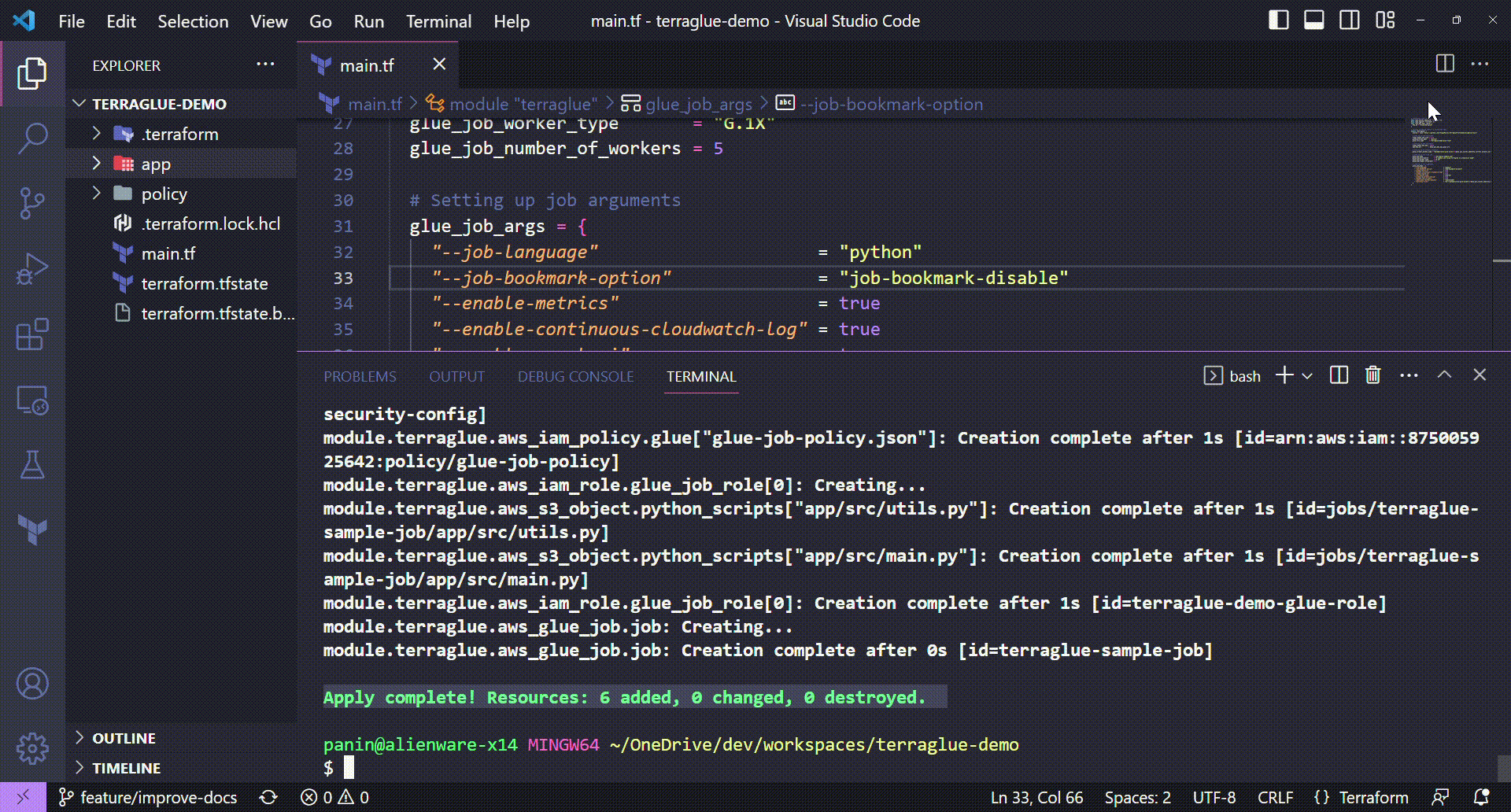
With terraform plan command, we will be able to see all the resources that will be deployed with the configuration we chose.
Running the terraform plan command
Terraform apply¶
And now we can finally deploy the infrastructure declared using the terraform apply command.
Running the terraform apply command
Deployed Resources¶
Well, to finish this demo page, let's see all the resources that were deployed by terraglue module call. In essence, we are talking about:
- An IAM role with permissions specified by a JSON file provided by users in the Terraform project
- Python scripts in a given S3 bucket to be used in a Glue job
- A Glue job with parameters and arguments chosen by users
A little tour through all deployed resources by terraglue
✅ I hope all the demos can help you somehow on using terraglue to configure and deploy your own Glue job in AWS. Keep reading the docs to become a master user in terraglue!